SortShuffleWriter 是最基础的ShuffleWriter, 当其他几个ShuffleWriter不满足条件,或存在mapSide的聚合时只能选择SortShuffleWriter,它是支持最全面的兜底ShuffleWriter。
SortShuffleWriter又是如何实现大数据量下的shuffleWriter过程呢?
SortShuffleWriter源码详解
在具体的实现上sortShuffleWriter也是被ShuffleWriteProcessor 类调用的,在ShuffleWriteProcessor 中实现了sortShuffleWriter的获取、 RDD write的写入和mapStatus的返回。具体可以参考Bypass文章[SPARK][CORE] 面试问题之 BypassMergeSortShuffleWriter的细节。
那我们详细介绍下sortShuffleWriter如何实现write的过程:
1// sortShuffleWriter
2override def write(records: Iterator[Product2[K, V]]): Unit = {
3// [1] 首先创建基于JVM的外排器ExternalSorter, 如果是需要mapSide聚合的,封装进去aggregator和ordering
4sorter= if (dep.mapSideCombine) {
5 new ExternalSorter[K, V, C](
6 context,dep.aggregator,Some(dep.partitioner),dep.keyOrdering,dep.serializer)
7 } else {
8 // In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
9 // care whether the keys get sorted in each partition; that will be done on the reduce side
10 // if the operation being run is sortByKey.
11 new ExternalSorter[K, V, V](
12 context, aggregator = None,Some(dep.partitioner), ordering = None,dep.serializer)
13 }
14// [2] mapTask的records全部insert到外部排序器
15sorter.insertAll(records)
16
17 // Don't bother including the time to open the merged output file in the shuffle write time,
18 // because it just opens a single file, so is typically too fast to measure accurately
19 // (see SPARK-3570).
20 // [3] 创建处理mapTask所有分区数据commit提交writer
21 val mapOutputWriter = shuffleExecutorComponents.createMapOutputWriter(
22dep.shuffleId, mapId,dep.partitioner.numPartitions)
23// [4] 将写入ExternalSorter中的所有数据写出到一个map output writer中
24sorter.writePartitionedMapOutput(dep.shuffleId, mapId, mapOutputWriter)
25// [5] 提交所有分区长度,生成索引文件
26partitionLengths= mapOutputWriter.commitAllPartitions(sorter.getChecksums).getPartitionLengths
27mapStatus=MapStatus(blockManager.shuffleServerId,partitionLengths, mapId)
28}
可以看到在sortShuffleWrite中主要有以下五个步骤:
[1] 首先创建基于JVM的外排器ExternalSorter, 如果是需要mapSide聚合的,封装进去aggregator和ordering
[2] mapTask的records全部insert到外部排序器
[3] 创建处理mapTask所有分区数据commit提交writer
[4] 将写入ExternalSorter中的所有数据写出到一个map output writer中
[5] 提交所有分区长度,生成索引文件
从这里可以看出完成排序和溢写文件的操作主要是在ExternalSorter外部排序器中。
在进一步的学习前,我们先来简单了解了ExternalSorter。
ExternalSorter是一个外部的排序器,它提供将map任务的输出存储到JVM堆中,同时在其内部封装了PartitionedAppendOnlyMap 和 PartitionedPairBuffer 用于数据的buffer, 如果采用PartitionedAppendOnlyMap 可以提供数据的聚合。此外其中还封装了spill , keyComparator, mergeSort 等提供了,使用分区计算器将数据按Key分组到不同的分区,然后使用比较器对分区中的键值进行排序,将每个分区输出到单个文件中方便reduce端进行fetch。
1// ExternalSorter
2def insertAll(records: Iterator[Product2[K, V]]): Unit = {
3 //TODO: stop combining if we find that the reduction factor isn't high
4val shouldCombine = aggregator.isDefined
5
6 // [1] 是否需要在mapSide的聚合
7 if (shouldCombine) {
8 // [1.1] 通过aggregator获取mergeValue和createCombiner
9 // Combine values in-memory first using our AppendOnlyMap
10 val mergeValue = aggregator.get.mergeValue
11 val createCombiner = aggregator.get.createCombiner
12 var kv: Product2[K, V] = null
13 val update = (hadValue: Boolean, oldValue: C) => {
14 if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
15 }
16 // [2] 如果需要map端聚合,将数据写入map缓存中
17 while (records.hasNext) {
18 addElementsRead()
19 kv = records.next()
20map.changeValue((getPartition(kv._1), kv._1), update)
21 maybeSpillCollection(usingMap = true)
22 }
23 } else {
24 // Stick values into our buffer
25 while (records.hasNext) {
26 addElementsRead()
27 val kv = records.next()
28 // [2] 如果不需要map端聚合,将数据写入buffer缓存中
29buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
30 // [3] 判断是否需要溢写,并进行溢写
31 maybeSpillCollection(usingMap = false)
32 }
33 }
34}
如上代码中所示,在insertAll中主要将数据写入缓存中,如果需要map端聚合的写入PartitionedAppendOnlyMap 数据结构中,如果不需要map端聚合的写入PartitionedPairBuffer 中,最后调用maybeSpillCollection进行溢写操作。
我们先看下两种数据结构的异同点:
PartitionedAppendOnlyMap中数据存储在父类AppendOnlyMap的data数组中,PartitionedPairBuffer数据就存在该类的data数组中;
PartitionedAppendOnlyMap间接的继承SizeTracker,PartitionedPairBuffer是直接继承SizeTracker,用来进行要记录数据采样大小,以便上层进行适时的申请内存以及溢写磁盘操作
AppendOnlyMap会对元素在内存中进行更新或聚合,而PartitionedPairBuffer不支持map端聚合操作,只起到数据缓冲的作用;
两者都实现了WritablePartitionedPairCollection,可以根据partitonId排序,也可以根据partitionId+key进行排序操作返回排序后的迭代器数据。
PartitionedAppendOnlyMap是继承自AppendOnlyMap 类并实现了SizeTracker 接口,其中SizeTracker通过对数据结构的采样对缓存大小进行估算的一种实现。AppendOnlyMap 是类似于HashMap的数据接口。主要针对java中的map不能缓存null值的情况,实现了基于array[]数组实现的k-v键值对缓存接口。
在AppendOnlyMap 中时将k-v依次放入到数组中缓存数据。在HASH冲突时,Java原生的HashMap是通过拉链法去解决hash冲突的,AppendOnlyMap是通过开放地址法–线性探测的方法进行解决冲突的,线性探测间隔总是固定的,通常为1。AppendOnlyMap支持key为null的情况,使用一个变量nullValue保存对应的值,haveNullValue表示是否存在null的key,如果之前不存在,就将size+1,然后更新值;存在时候只需要更新值即可;另外一点和java的HashMap不同的是,AppendOnlyMap提供了聚合的方法,来应对shuffle过程中指定了map-side聚合的情况,使用者需要提供updateFunc 。
由于PartitionedPairBuffer只是一个数据缓冲区,不需要对元素进行聚合操作等,所以添加元素直接将元素append到数组的back即可,不过需要先判断数据容量是否已经满了,满了则需要扩容。然后首先会将
总而言之,AppendOnlyMap的行为更像map,元素以散列的方式放入data数组,而PartitionedPairBuffer的行为更像collection,元素都是从data数组的起始索引0和1开始连续放入的。
了解了map和buffer两种数据结构,那么接下来我们学习下它是如何进行溢出处理的?
1// ExternalSorter
2private def maybeSpillCollection(usingMap: Boolean): Unit = {
3 var estimatedSize = 0L
4 if (usingMap) {
5 // [1] 估算当前缓存数据结构的size
6 estimatedSize =map.estimateSize()
7 // [2] 判断是否需要溢写,如果执行溢写后,会重新创建缓存数据结构
8 if (maybeSpill(map, estimatedSize)) {
9map= new PartitionedAppendOnlyMap[K, C]
10 }
11 } else {
12 estimatedSize =buffer.estimateSize()
13 if (maybeSpill(buffer, estimatedSize)) {
14buffer= new PartitionedPairBuffer[K, C]
15 }
16 }
17 // [3] 记录当前的峰值内存
18 if (estimatedSize >_peakMemoryUsedBytes) {
19_peakMemoryUsedBytes= estimatedSize
20 }
21}
判断是否需要溢出主要有以下三步:
[1] 估算当前缓存数据结构的size
[2] 判断是否需要溢写,如果执行溢写后,会重新创建缓存数据结构
[3] 记录当前的峰值内存
在执行spill前会先尝试申请内存,不满足才会进行溢出:
1protected def maybeSpill(collection: C, currentMemory: Long): Boolean = {
2 var shouldSpill = false
3 // [1] 如果当前的记录数是32的倍数, 同时当前内存超过了门限,默认5M
4 if (elementsRead % 32 == 0 && currentMemory >=myMemoryThreshold) {
5 // Claim up to double our current memory from the shuffle memory pool
6 // [2] 尝试申请2倍当前内存,并将门限调整为两倍当前内存
7 val amountToRequest = 2 * currentMemory -myMemoryThreshold
8val granted = acquireMemory(amountToRequest)
9myMemoryThreshold+= granted
10 // If we were granted too little memory to grow further (either tryToAcquire returned 0,
11 // or we already had more memory than myMemoryThreshold), spill the current collection
12 // [3] 如果没申请下来,则应该进行spill, 或者当前写入的records数大于了强制spill门限,默认是整数的最大值
13 shouldSpill = currentMemory >=myMemoryThreshold
14}
15 shouldSpill = shouldSpill ||_elementsRead>numElementsForceSpillThreshold
16 // [4] 进行spill
17// Actually spill
18 if (shouldSpill) {
19_spillCount+= 1
20 logSpillage(currentMemory)
21 spill(collection)
22_elementsRead= 0
23_memoryBytesSpilled+= currentMemory
24 releaseMemory()
25 }
26 shouldSpill
27}
在真正溢写数据之前,writer会先申请内存扩容,如果申请不到或者申请的过少,才会开始溢写。这符合Spark尽量充分地利用内存的中心思想。
另外需要注意的是,传入的currentMemory参数含义为“缓存的预估内存占用量”,而不是“缓存的当前占用量”。这是因为PartitionedAppendOnlyMap与PartitionedPairBuffer都能动态扩容,并且具有SizeTracker特征,能够通过采样估计其大小。
负责溢写数据的spill()方法是抽象方法,其实现仍然在ExternalSorter中。
1// ExternalSorter
2override protected[this] def spill(collection: WritablePartitionedPairCollection[K, C]): Unit = {
3 //【根据指定的比较器comparator进行排序,返回排序结果的迭代器】
4 //【如果细看的话,destructiveSortedWritablePartitionedIterator()方法最终采用TimSort算法来排序】
5 val inMemoryIterator = collection.destructiveSortedWritablePartitionedIterator(comparator)
6 //【将内存数据溢写到磁盘文件】
7 val spillFile = spillMemoryIteratorToDisk(inMemoryIterator)
8 //【用ArrayBuffer记录所有溢写的磁盘文件】
9 spills += spillFile
10 }
那么sortShuffleWriter是如何将in-memory中的数据溢写到磁盘的?
1/**
2 * Spill contents of in-memory iterator to a temporary file on disk.
3 */
4private[this] def spillMemoryIteratorToDisk(inMemoryIterator: WritablePartitionedIterator[K, C])
5 : SpilledFile = {
6 // Because these files may be read during shuffle, their compression must be controlled by
7 // spark.shuffle.compress instead of spark.shuffle.spill.compress, so we need to use
8 // createTempShuffleBlock here; see SPARK-3426 for more context.
9 // [1] 创建临时的blockid和对应的file
10 val (blockId, file) =diskBlockManager.createTempShuffleBlock()
11
12 // These variables are reset after each flush
13 var objectsWritten: Long = 0
14 val spillMetrics: ShuffleWriteMetrics = new ShuffleWriteMetrics
15 // [2] 创建个DiskBlockObjectWriter的写出流
16 val writer: DiskBlockObjectWriter =
17blockManager.getDiskWriter(blockId, file,serInstance,fileBufferSize, spillMetrics)
18
19 // List of batch sizes (bytes) in the order they are written to disk
20 val batchSizes = new ArrayBuffer[Long]
21
22 // How many elements we have in each partition
23 val elementsPerPartition = new Array[Long](numPartitions)
24
25 // Flush the disk writer's contents to disk, and update relevant variables.
26 // The writer is committed at the end of this process.
27 def flush(): Unit = {
28 val segment = writer.commitAndGet()
29 batchSizes += segment.length
30_diskBytesSpilled+= segment.length
31 objectsWritten = 0
32 }
33
34 var success = false
35 try {
36 // [3] 遍历内存数据结构中的数据,在调用writeNext迭代器时会根据comparator按key排序,缓存中的key为(partitionId, key), 会先按分区排序,再按key排序。
37 while (inMemoryIterator.hasNext) {
38 val partitionId = inMemoryIterator.nextPartition()
39require(partitionId >= 0 && partitionId 40 s"partition Id:${partitionId} should be in the range [0,${numPartitions})")
41 inMemoryIterator.writeNext(writer)
42 // [3.1] 记录每个分区的元数数
43 elementsPerPartition(partitionId) += 1
44 objectsWritten += 1
45 // [3.2] 默认每1000条生成一个fileSegement
46 if (objectsWritten ==serializerBatchSize) {
47 flush()
48 }
49 }
50 if (objectsWritten > 0) {
51 flush()
52 writer.close()
53 } else {
54 writer.revertPartialWritesAndClose()
55 }
56 success = true
57 } finally {
58 if (!success) {
59 // This code path only happens if an exception was thrown above before we set success;
60 // close our stuff and let the exception be thrown further
61 writer.revertPartialWritesAndClose()
62 if (file.exists()) {
63 if (!file.delete()) {
64 logWarning(s"Error deleting${file}")
65 }
66 }
67 }
68 }
69// [4] 最终将溢写的文件封装为SpilledFile返回
70SpilledFile(file, blockId, batchSizes.toArray, elementsPerPartition)
71}
实现溢写有四个步骤:
[1] 创建临时的blockid和对应的file
[2] 创建个DiskBlockObjectWriter的写出流
[3] 遍历内存数据结构中的数据,在调用writeNext迭代器时会根据comparator按key排序,缓存中的key为(partitionId, key), 会先按分区排序,再按key排序。
[3.1] 记录每个分区的元素数
[3.2] 默认每1000条,进行一次flush生成一个fileSegement
[4] 最终将溢写的文件封装为SpilledFile返回
从这里可以看出spillMemoryIteratorToDisk是真正的溢写类,其完成了数据的排序和溢写。从上面代码可以看出,这里只创建了一个临时文件,一个DiskBlockObjectWriter写出流。这相比于Bypass的为每个分区创建一个io流和临时文件, 是少了许多。这得益于其基于缓存的排序,首先按partitionid排序,然后按key排序,天然的将不同的分区聚集到了一起。
在溢写的过程中,如果满足溢写的条件就会溢写出一个SpilledFile,或产生很多文件,最终是如何汇总实现的呢?那我们看看sortShuffle是如何将写入ExternalSorter中的所有数据写出到一个map output writer中吧。
由于代码太长,我们跳过spills.isEmpty的情况,这种情况下我们不复杂就是将缓存中的数据排序写出就完成了,我们主要看下存在溢写的情况:
1// ExternalSorter
2def writePartitionedMapOutput(
3 shuffleId: Int,
4 mapId: Long,
5 mapOutputWriter: ShuffleMapOutputWriter): Unit = {
6 var nextPartitionId = 0
7 if (spills.isEmpty) {
8 // Case where we only have in-memory data
9 val collection = if (aggregator.isDefined)mapelsebuffer
10val it = collection.destructiveSortedWritablePartitionedIterator(comparator)
11 while (it.hasNext) {
12 ...
13 }
14 } else {
15 // We must perform merge-sort; get an iterator by partition and write everything directly.
16 // [1] 调用分区迭代器,将分区数据生成(id, elements)二元组
17 for ((id, elements) <- this.partitionedIterator) {
18 val blockId =ShuffleBlockId(shuffleId, mapId, id)
19 var partitionWriter: ShufflePartitionWriter = null
20 var partitionPairsWriter: ShufflePartitionPairsWriter = null
21 TryUtils.tryWithSafeFinally{
22 // 每个分区打开的writer进行并发写入的优化,最终生成一个文件
23 partitionWriter = mapOutputWriter.getPartitionWriter(id)
24 partitionPairsWriter = new ShufflePartitionPairsWriter(
25 partitionWriter,
26serializerManager,
27serInstance,
28 blockId,
29 context.taskMetrics().shuffleWriteMetrics,
30 if (partitionChecksums.nonEmpty)partitionChecksums(id) else null)
31 if (elements.hasNext) {
32 for (elem <- elements) {
33 partitionPairsWriter.write(elem._1, elem._2)
34 }
35 }
36 } {
37 if (partitionPairsWriter != null) {
38 partitionPairsWriter.close()
39 }
40 }
41 nextPartitionId = id + 1
42 }
43 }
44
45 context.taskMetrics().incMemoryBytesSpilled(memoryBytesSpilled)
46 context.taskMetrics().incDiskBytesSpilled(diskBytesSpilled)
47 context.taskMetrics().incPeakExecutionMemory(peakMemoryUsedBytes)
48}
下面是分区迭代器的具体实现代码:
1// ExternalSorter
2def partitionedIterator: Iterator[(Int, Iterator[Product2[K, C]])] = {
3 val usingMap = aggregator.isDefined
4 val collection: WritablePartitionedPairCollection[K, C] = if (usingMap)mapelsebuffer
5// [1] 如果没有溢写,直接groupByPartition
6if (spills.isEmpty) {
7 // Special case: if we have only in-memory data, we don't need to merge streams, and perhaps
8 // we don't even need to sort by anything other than partition ID
9 if (ordering.isEmpty) {
10 // The user hasn't requested sorted keys, so only sort by partition ID, not key
11 groupByPartition(destructiveIterator(collection.partitionedDestructiveSortedIterator(None)))
12 } else {
13 // We do need to sort by both partition ID and key
14 groupByPartition(destructiveIterator(
15 collection.partitionedDestructiveSortedIterator(Some(keyComparator))))
16 }
17 } else {
18 // [2] 存在溢写,需要先将在内存中和溢写文件中的数据封装为迭代器执行归并排序, 归并排序时通过最小堆实现的
19 // Merge spilled and in-memory data
20 merge(spills.toSeq, destructiveIterator(
21 collection.partitionedDestructiveSortedIterator(comparator)))
22 }
23}
从整个shuffle write流程可知,每一个ShuffleMapTask不管是否需要mapSide的聚合都会将数据写入到内存缓存中,如果申请不到内存或者达到强制溢出的条件,则会将缓存中的数据溢写到磁盘,在溢写前会使用TimSort对缓存中的数据进行排序,并将其封装为SpilledFile返回,此时溢写文件中的数据是可能存在多个分区的数据的。
在输出之前会将写入到ExternalSort中的数据写出到一个map output Writer中。写出时如果存在溢写,会分别从SpilledFile和缓存中获取对应分区的迭代器,交由归并排序实现数据的合并,这里的归并排序使用的是最小堆,然后在将其交由最终output Writer进行写出。最后提交文件和各分区长度,生成索引文件。
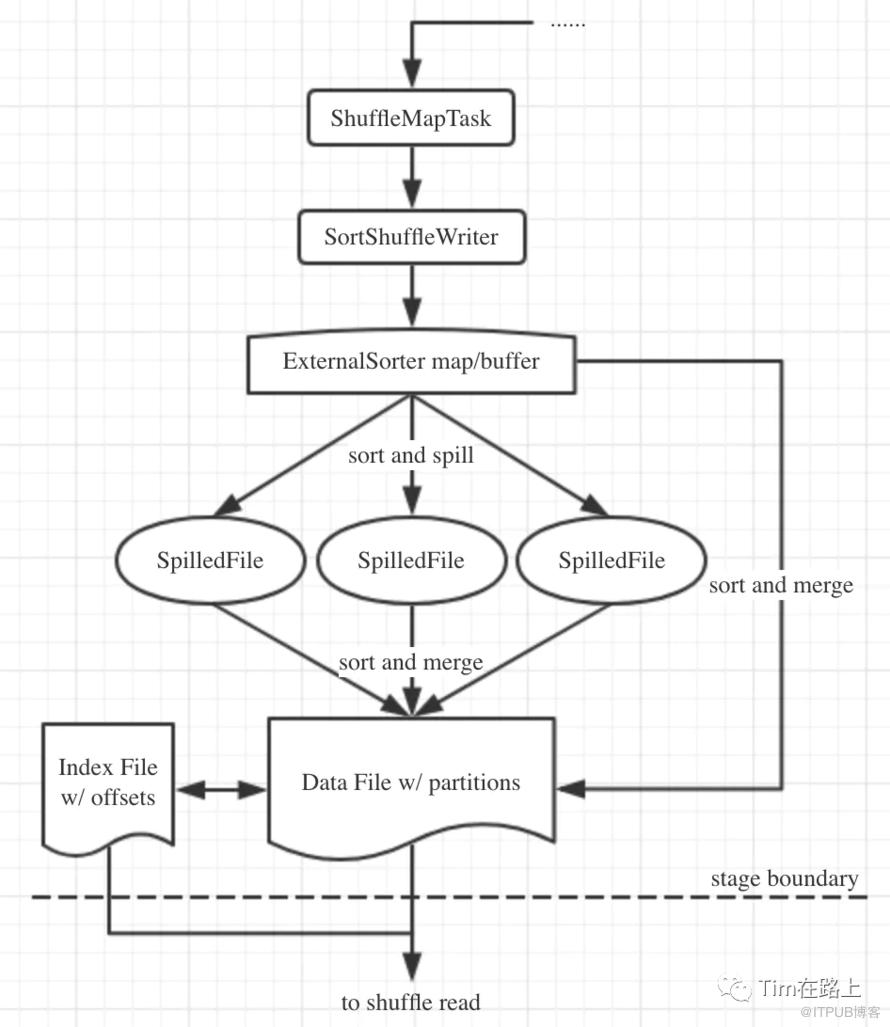
总之,通过SortShuffleWriter只会产生两个文件,一个分区的数据文件,一个索引文件。整个sortshuffleWriter过程只会产生2 * M 个中间文件。
今天就先到这里,通过上面的介绍,我们也留下些面试题:
如果数据全部写到缓存buffer中,如何实现最终的归并排序?那么如果存在溢写数据,又如何实现归并排序?SortShuffleWriter 是如何实现的?
SortShuffleWriter 中实现了数据排序,那么最终形成的结果是全局有序的吗?
一句话简单说下SortShufflerWriter的实现过程?