本文的背景是:大学关系很好的老师问我能不能把Excel中1000个超链接网址对应的pdf文档下载下来。
读取数据
模拟登录网址点击下载pdf的按钮
写循环批量下载所有文件

首先读取数据,代码如下:
import osimport numpy as npimport pandas as pd#设置文件存放的地址os.chdir(r'F:\老师\下载文件')#读取数据link_date = pd.read_csv('import.csv',encoding='gbk')link_date.head(2)


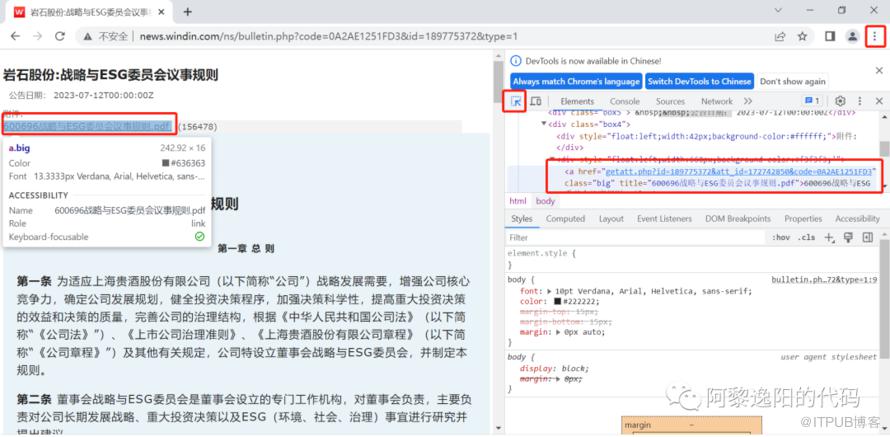
接着模拟使用Chrome浏览器登录,用代码打开第一个网址,并模拟人进行点击下载,具体代码如下:
import jsonimport timeimport randomfrom captcha import *from datetime import datetimefrom selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support import waitfrom selenium.webdriver.common.keys import Keysfrom selenium.common.exceptions import NoSuchElementExceptionfrom selenium.webdriver.common.action_chains import ActionChainsfrom selenium.webdriver.support import expected_conditions as EC#导入库print('程序开始时间:', datetime.now().strftime("%Y-%m-%d %H:%M:%S"))#模拟使用Chrome浏览器登陆options = webdriver.ChromeOptions()options.add_argument("--disable-blink-features=AutomationControlled")driver = webdriver.Chrome(options=options)driver.implicitly_wait(10)#打开搜索页driver.get(link_date['网址'][0])time.sleep(20) # 暂停20s#点击下载pdf的按钮driver.find_element_by_xpath('//*[@id="mdiv"]/div[3]/div[2]/a').click()

写循环批量下载所有文件,最简单的方式是遍历所有网址,模拟点击下载pdf,代码如下:
for i in range(0,1000):print(i)#打开搜索页driver.get(link_date['超链接'][i])time.sleep(20) # 暂停20sdriver.find_element_by_xpath('//*[@id="mdiv"]/div[3]/div[2]/a').click()
但是这个代码有一个问题,一旦有一个网址出现意外,容易代码中断,会得到如下报错:
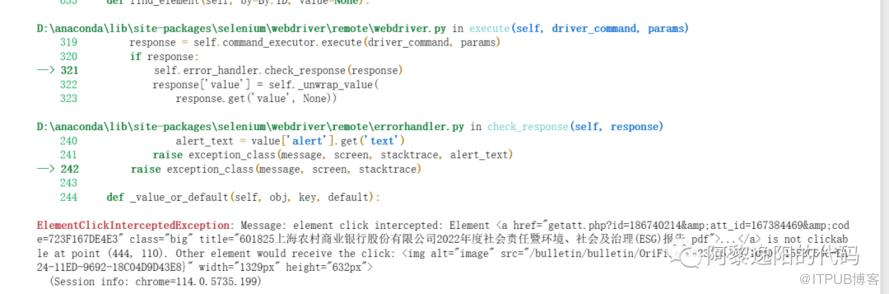
lab = []for i in range(1, 1000):try:print(i)#打开搜索页driver.get(link_date['网址'][i])time.sleep(20) # 暂停20sdriver.find_element_by_xpath('//*[@id="mdiv"]/div[3]/div[2]/a').click()lab.append(i)except:pass
至此,Python批量爬虫下载PDF文件代码实现已经讲解完毕,感兴趣的同学可以自己实现一遍 。
。
【Python】【爬虫】最近想买电脑,用Python爬取京东评论做个参考


扫一扫关注我
19967879837
联系微信号、手机号