点击上方蓝字加入我们


本系列文章是原作者Rohit Patel的长篇雄文《Understanding LLMs from Scratch Using Middle School Math-A self-contained, full explanation to inner workings of an LLM》的深度学习与解读笔记。本篇是系列第七篇。我们强烈建议您在开始前阅读并理解前文(点击下方目录)。
7. Softmax
8. 残差连接(Residual connections)
9. 层归一化(Layer Normalization)
10. Dropout
11. 多头注意力(Multi-head attention)
12. 位置嵌入(Positional embeddings)
13. GPT 架构
14. Transformer 架构
7
Softmax函数 - “概率”的起源
01
困境来自哪里?
02
为什么需要“概率”?

03
Softmax函数如何工作?
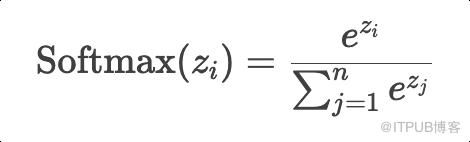
所有概率值都在 (0,1) 之间。 所有概率值的总和严格等于 1。 -
原始分值的大小关系被保留(即分数高的选项概率一定更高)。
e² ≈ 7.389
e¹ ≈ 2.718
-
e⁰·¹ ≈ 1.105
为什么必须用指数函数?
差异放大:能够放大决策信号
正数保障:无论输入正负,结果永远为正
-
单调性:能够保持原来数值的大小顺序
还有一个特征,暂时我们知道就好:由于e指数函数的导数等于其自身,反向传播时能简化梯度计算。
2. 归一化计算概率:
将指数计算后的值相加:
7.389+2.718+1.105≈11.212
那么每个值的概率就是:
“2”的概率:7.389/11.212 ≈ 65.9%
“1”的概率:2.718/11.212 ≈ 24.2%
-
"0.1"的概率:1.105/11.212 ≈ 9.9%
很显然,这样计算的结果一定小于1,且总和严格等于1,符合概率要求
04
Softmax函数的价值
截至目前,我们已经知道Softmax在语言模型中的两个典型应用:输出层预测与注意力机制(计算注意力权重)。
是否还有其他意义呢?
Softmax把神经网络的输出转化为概率,而不是直接选择最高分的那个选项。更大的价值是:让模型在生成过程中可以根据概率探索更多样的可能。
1. 简单决策的问题
"m":得分较高(例如0.45) "u":得分最高(例如0.5) -
其他字符(如"a", "b"等):得分极低(例如0.05)
"u":50%的概率 "m":45%的概率 -
其他字符:5%的概率
05
一个熟悉的参数:温度(Temperature)

这个参数T用来控制转化后的概率的结果。简单的说就是:
-
低温(T较小):Softmax输出的概率分布更尖锐,模型更倾向于选择得分最高的选项,生成结果更确定,更保守,多样性较低。
-
高温(T较大):Softmax输出的概率分布更平缓与均匀,模型更愿意尝试多样化的选项,生成结果更具创造性。
这就好比你在选择外卖,如果两家餐厅的评分为5分和1分,你会毫不犹豫的选择5分的;而如果它们的评分分别为4.9和4.7,你可能更愿意轮流尝试不同的餐厅。
以上就是Softmax函数的介绍,虽然易于理解,但却意义重大,是语言模型生成时的“决策导航仪”。通过概率转化,Softmax赋予了语言模型一种"智慧":在犯错时有机会修正,在探索时保持多样性。
欢迎继续关注下一期,喜欢就点个赞吧!
THE END
福利时间
为了帮助LLM开发人员更系统性与更深入的学习RAG应用,特别是企业级的RAG应用场景下,当前主流的优化方法与技术实现,我们编写了《基于大模型的RAG应用开发与优化 — 构建企业级LLM应用》这本长达500页的开发与优化指南,与大家一起来深入到LLM应用开发的全新世界。
更多细节,点击链接了解
