点击上方蓝字关注我们


本系列文章是原作者Rohit Patel的长篇雄文《Understanding LLMs from Scratch Using Middle School Math-A self-contained, full explanation to inner workings of an LLM》的深度学习与解读笔记。本篇是系列第五篇。我们强烈建议您在开始前阅读并理解前文(点击下方目录)。
5. 子词分词器(Sub-word tokenizers)
6. 自注意力机制(Self-attention)
7. Softmax
8. 残差连接(Residual connections)
9. 层归一化(Layer Normalization)
10. Dropout
11. 多头注意力(Multi-head attention)
12. 位置嵌入(Positional embeddings)
13. GPT 架构
14. Transformer 架构
5
子词分词器


如果用“token”(相信你很熟悉这个词)来代表嵌入(即分配向量)的基本单位,那么之前模型使用单个字符作为token,现在我们则提出使用整个单词作为token。

一、从字符到词语的进化之路
The cat sat on the mat. -
The cats ate the fish.
"cat"和"cats"共享前三个字符 -
"sat"和"ate"都包含"at"但含义不同
二、子词分词的魔法原理
"unhappy" → ["un", "happy"] "cats" → ["cat", "s"] -
"中文分词" → ["中", "文", "分", "词"](注:实际处理会更智能)
-
共享零件,举一反三
当模型学会"happy"表示开心,"un"表示否定,它就能自动理解"unhappy"、"unfriendly"等系列词汇,而不需要逐个记忆。这就像掌握"氵"偏旁后,能猜出"江""河""湖"都和水有关。 -
应对生僻词
遇到"ChatGPT"这种新造词时,子词分词可以将其拆解为["Chat","G","P","T"],模型立即明白这与聊天程序相关。传统方法遇到新词就只能抓瞎。 -
平衡效率与效果
主流子词分词器(如BERT用的WordPiece、GPT用的BPE)通常只保留3-5万个常用子词。对比整词分词的18万词库,存储量减少80%以上,却覆盖了更广泛的语言现象。
OpenAI的GPT-3使用BPE分词器后,即便面对网络俚语"LOLcats"也能游刃有余地拆解为["LOL","cat","s"],既理解这是搞笑猫图,又保持语法正确性。
三、分词器的工程实践
以"underground"为例,可能有多种切法:
["under","ground"](在地下) -
["un","der","ground"](不接地)
不同于英文的空格分隔,中文分词更具挑战。优秀的分词器要能区分:
"南京市长江大桥" → ["南京","市","长江","大桥"] -
而不是错误拆分为["南京","市长","江大桥"]
现代分词器如SentencePiece采用统一编码:
将文本转换为Unicode字符 统计高频字符组合,逐步合并为子词 -
最终形成包含单字、词语、词缀的混合词表
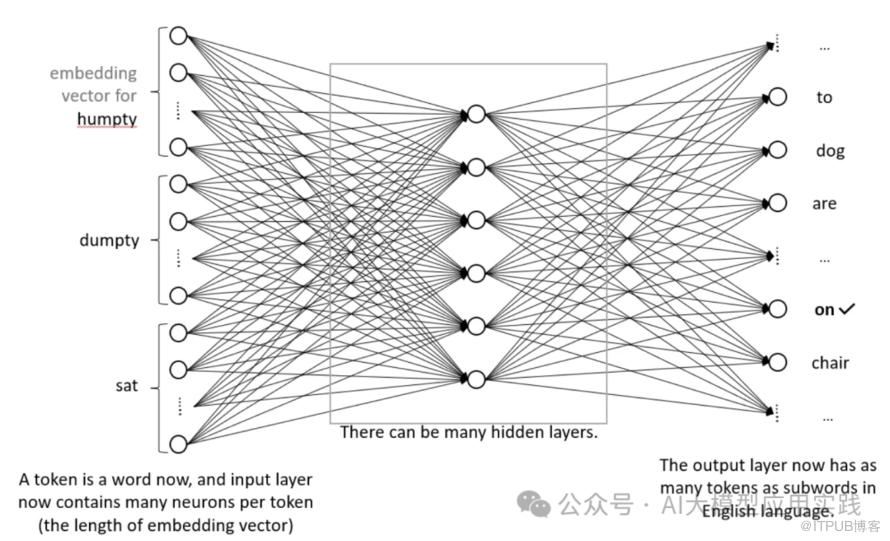
最后:
THE END
福利时间
为了帮助LLM开发人员更系统性与更深入的学习RAG应用,特别是企业级的RAG应用场景下,当前主流的优化方法与技术实现,我们编写了《基于大模型的RAG应用开发与优化 — 构建企业级LLM应用》这本长达500页的开发与优化指南,与大家一起来深入到LLM应用开发的全新世界。
更多细节,点击链接了解
此处购买享5折优惠
