本系列文章是原作者Rohit Patel的长篇雄文《Understanding LLMs from Scratch Using Middle School Math-A self-contained, full explanation to inner workings of an LLM》的深度学习与解读笔记。本篇是系列第三篇。我们强烈建议您在开始前阅读并理解前文(点击下方目录)。
5. 子词分词器(Sub-word tokenizers)6. 自注意力机制(Self-attention)8. 残差连接(Residual connections)9. 层归一化(Layer Normalization)11. 多头注意力(Multi-head attention)12. 位置嵌入(Positional embeddings)借助基本的中学数学知识,我们已经了解到什么是神经网络模型,以及一个神经网络模型大致是如何被训练的。这个训练好的神经网络可以被用于预测一组数据代表的是“叶子”还是“花”,如果你愿意,它甚至可以被训练用来预测“未来一小时的天气”,只要有正确的权重设置:
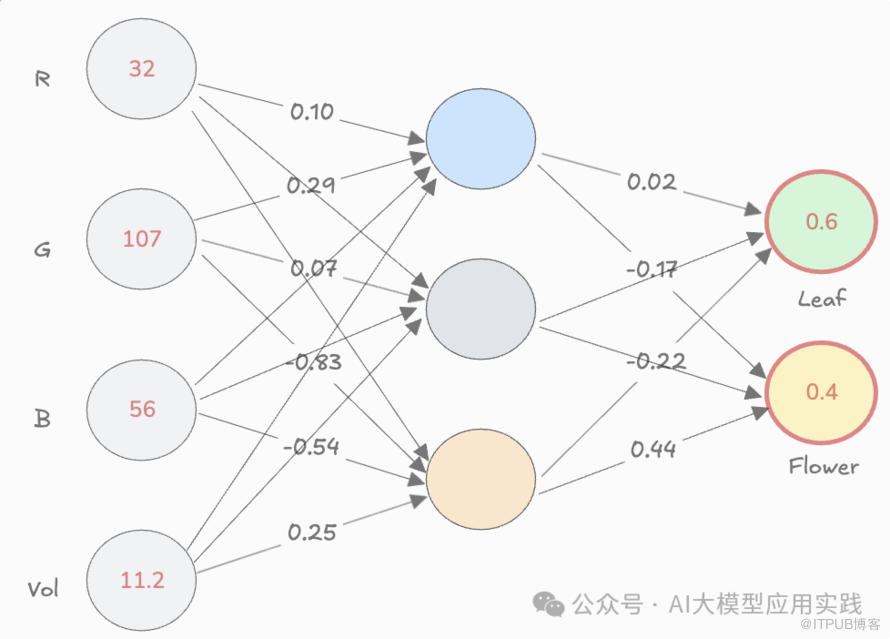
但我们需要研究的是语言模型(LLM),而不是一个预测模型。那么问题来了:
这个可以预测“叶子”与“花”的神经网络模型如何用来生成自然语言呢?
方法很简单。上图已经展示了神经网络的本质:输入一些数字,经过模型内部的数学计算(基于训练好的参数,主要是权重,即各层之间连线上的数字),输出另一些数字。 而这些输入和输出的数字代表什么,完全取决于你如何解释和训练。例如:
- 在之前的例子中:输入的数字代表一个事物的4个属性(RGB,以及体积),输出的数字则被解释为该物体是“叶子”还是“花”的概率
-
你也可以训练另一个神经网络,将输入的数字代表当前的天气数据如云量、湿度等,而输出的数字则被解释为未来一小时内会“下雨“还是”转晴“
所以,你当然也可以训练一个神经网络模型,将输入的数字代表一个句子的前几个字符,而输出的数字则被解释为这个句子的下一个字符的概率。与预测叶子或花的二分类不同,自然语言输出的字符要多得多,以英文字符为例,数量远多于 2。假设我们需要预测下一个英文字符是什么,那么可以设计神经网络的 输出层至少要包含 26 个神经元(其实还需要考虑一些符号如空格、句号等),让每个神经元对应一个英文字母(或符号),并将输出层每个神经元的数字解释为对应字母的概率。即:输出层中数值最大的神经元对应的字母就是预测的下一个字符。举一个例子,假设输入的内容是 “I love y”,经过我们的训练并设置好正确的权重,现在神经网络的输出如下: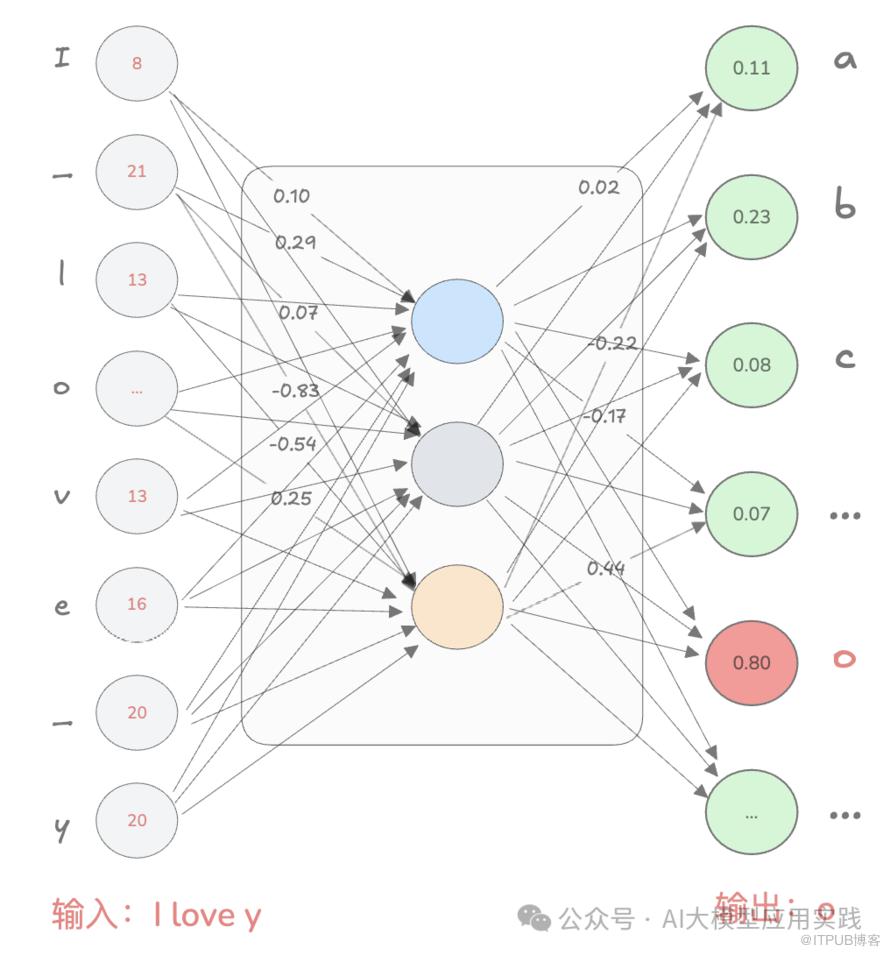
a=0.11, b=0.23,c=0.08 …, o=0.80,...我们选择数值最大的神经元(0.80),对应字母 “o”,也就是预测的下一个字符就是 “o”,于是现在我们可以把内容变成:由于神经网络只能接收数字输入,无法直接理解字符。因此需要将输入的字符序列(如 “I love y”)转化为数字。一种简单的方法是:给每个输入字符分配一个数字,比如 a=1, b=2, …, z=26,空格用 27 表示等等。那么如果你需要输入“I love y",则对应输入层神经元的各个值为:现在,我们已经拥有了一个设置好权重的神经网络,能够准确预测下一个字符。这里我们输入了字符"I love y"(实际输入[9,27,12,15,22,5,27,25]),预测了下一个字符“o“(实际输出是每个字符的概率,o的概率最大)。那么如何生成完整的句子呢?
- 将预测的 “o” 加入输入中,形成新的序列 “I love yo”。
- 将新的序列“I love yo"输入到神经网络,预测出下一个字符“u"。
-
依此类推,不断重复这个过程,最后我们递归生成了一个句子“I love you so much"。
这种方式下,神经网络就具备了生成自然语言的能力,成为一个非常基础的生成式 AI 语言模型。你可能会敏锐的发现一个问题,由于神经网络的输入层大小是固定的,比如只能接受 8 个字符,也就是可以接受"I love y"的每一个字符。但是当我们预测了第一个字符"o"以后,就无法把完整的"I love yo"这9个字符输入到神经网络,除非你重新修改整个神经网络并训练出权重,但很显然这是不可行的。解决方法是:用类似队列(queue)“先进先出”的方式保持固定的队列大小,也可以想象成一种“滑动窗口”。就是把最开始的第一个字符"I"踢出去,只发送最近的8个字符,即“_love_yo",然后预测出"u";接着再输入"love_you",预测出空格...。类似下图(为了方便查看,这里空格用_表示),输入的灰色字符表示在本轮被丢弃:
因此,如果最后生成 “I love you so much”,到最后生成"h"时,前面的"i_love_yo"字符在输入时已经被丢弃。所以,这样的设计会导致神经网络逐渐“遗忘”早期的信息,尤其在生成长句子时,会影响预测质量。这种固定的输入到神经网络的长度也被称为上下文长度,即提供给神经网络模型用来预测的最大输入长度。现代神经网络已经显著提高了上下文长度(数千上万个单词),因此模型可以参考更多上下文来生成更连贯的文本。这里还有一个问题:当输入字符时,我们用简单的数字编码(如 “i” = 9);而在输出时,神经网络需要输出多个数字(即代表不同字符概率的数值),并挑选最大的那个,为什么不使用相同的编码方式呢?比如预测出"o",那么就直接输出数字15?原因是:不同的输入和输出解释,更有助于模型的训练和表现。而事实证明,目前已知的最有效的输入输出的解释方式也是不同的。这是因为:
-
输入:在输入时,通常希望信息尽可能精确并方便处理,事实上,这里的简单输入数字的方式也不是最优的,一些更复杂的编码方式(如嵌入向量)能更有效地表达字符之间的关系,后面还会介绍。
-
输出:使用多个神经元,每个代表一个可能的字符(概率),能更灵活地让模型量化每个候选字符的输出情况,也更容易优化。
所以,输入的重点是表达清楚,方便模型理解复杂的关系;而输出的重点是表达不确定性,让模型更好的预测多种可能性并不断优化。因为自然语言中充满复杂关系,灵活地选择输入输出的解释方式,能让模型更容易应对这些复杂性。这种不对称设计,是现代语言模型(如 GPT 等)获得高效性能的关键。
- 神经网络的核心任务是“输入一些信息,输出预测结果”。
- 如果输入是 “I love y”,神经网络就预测 “o”。一旦预测出 “o”,它会把“o”加入原字符,接着输入,继续预测出后续字符。
- 神经网络通过不断预测下一个字符,像“接龙”一样,逐步”生成“完整的句子。
-
虽然神经网络固定了每次输入的字符长度,但现代技术已经能让它记住更多上下文,从而生成更连贯的文本。
这个过程,从简单的分类预测,延伸到了语言生成,构成了现代语言模型的核心思想。当然,这个能力还远远不够,还需要大量的创新来使得这种简单的生成式AI迈向更像人类的智能对话模型。这涉及到一系列的关键要素,下篇我们将学习其中之一:嵌入(Embeddings)。为了帮助LLM开发人员更系统性与更深入的学习RAG应用,特别是企业级的RAG应用场景下,当前主流的优化方法与技术实现,我们编写了《基于大模型的RAG应用开发与优化 — 构建企业级LLM应用》这本长达500页的开发与优化指南,与大家一起来深入到LLM应用开发的全新世界。
更多细节,点击链接了解
此处购买享5折优惠


