
新年快乐

本篇介绍Anthropic的最新文章《Build effective agents》中的五种Agent Workflows基础模式中的Orchestrator - Workers(编排者-工作者)模式。

回顾请翻阅:
理解Orchestrator-Workers模式
编排者-工作者模式是这样一种模式:由一个LLM调用对任务进行分解,并将分解后的子任务交给多个“增强LLM”一起完成,最后将子任务的响应合并输出。
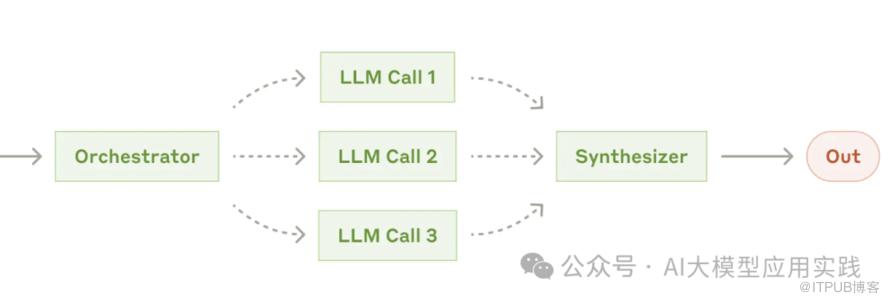
编排者-工作者模式适用于需要将一个相对复杂的任务动态拆解成多个子任务同时完成,以达到丰富任务输出并提高任务效率的目的。比如:
从多个不同方面思考与创作文案内容
需要同时开展的复杂编码任务
-
从多个不同来源搜索信息形成数据报告
尽管这种模式并不复杂,但是需要注意与另外两个模式的区别:
【与路由&并行模式的区别】
-
与路由模式的相同点在于开始具体任务之前都需要一次LLM调用;不同点在于:路由模式是把任务“转交”给“一个”下游任务分支,而编排模式则需要把任务”分解”后交给“多个”下游分支完成。
-
与并行模式的区别在于:并行模式的并行任务是可预测、预定义的,因此无需借助LLM来分解;而编排模式的并行任务是无法预测、动态的,因此需要借助LLM(编排器)来分解。
【区分多Agent系统的Supervisor模式】
在多Agent系统中有一个在拓扑上类似的Supervisor模式。即一个管理Agent来负责任务的分配与组织,多个工作Agent配合完成具体工作:
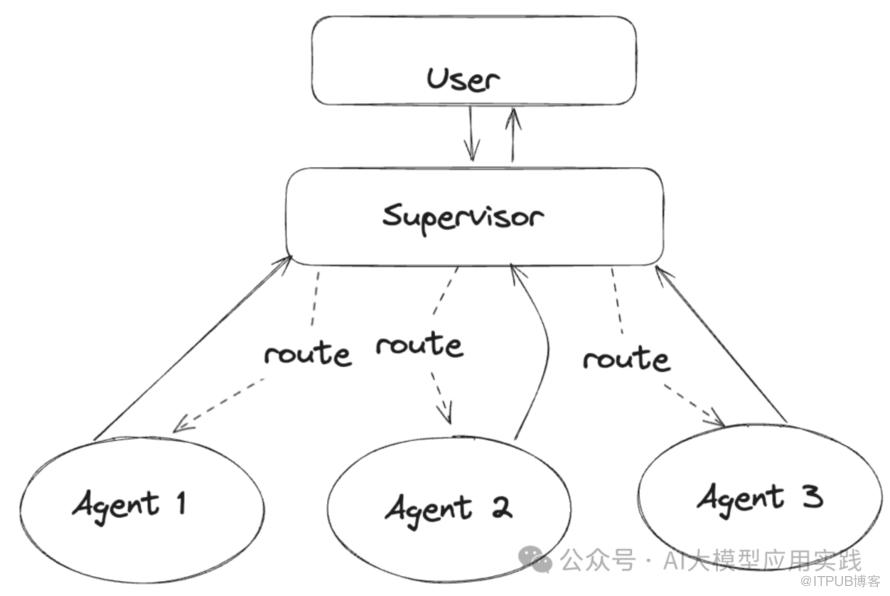
这里的区别是:
-
Supervisor Agent是一个具有自主任务规划能力的智能体。因此其不是简单的分解子任务,更需要规划多个子任务完成的步骤与路径
-
所以,Supervisor Agent拆分出的子任务通常不是并行,而是多步顺序完成
-
Supervisor Agent的子任务规划通常是动态的。即:根据上一个子任务完成后的环境状态,推理出下一个子任务及其Worker
-
所以,这种模式下子任务的输出需要返回给Supervisor以用于下一步的决策
记住,在Anthropic阐述的这套体系里,Workflows是不具备自主的多步骤任务规划能力的,那是Agents的能力。其降低了LLM带来的不确定性,当然也牺牲了灵活性。
实现Orchestrator-Workers模式
现在来实现这种模式,我们仍然借助Pydantic AI来简化实现过程,以方便做结构化输出与校验。
1. 首先定义编排器输出类型
Pydantic AI的好处是天然的类型安全性,非常适合LLM的结构化输出。这里输出的主要类型是子任务(Task):
# 定义任务模型
class Task(BaseModel):
type: str = Field(..., description='任务类型。即用来区分子任务的某个具体角度')
description: str = Field(..., description='执行此任务的清晰描述与要求。')
# 定义编排器响应模型
class OrchestratorResponse(BaseModel):
analysis: str = Field(..., description='解释你对任务的理解,判断应该从哪个角度分解任务, 并说明不同子任务如何服务于不同的角度。')
tasks: List[Task] = Field(..., description="任务列表")2. 配置提示词与模型
给编排器与工作器配置提示词与模型:
# 全局配置
config = {
'orchestrator': {
'system_prompt': '分析输入任务并将其分解为3-5种不同的并行子任务。',
'model': OpenAIModel(model_name='gpt-4o-mini')
},
'worker': {
'system_prompt': '根据任务描述与要求完成并输出。',
'model': OpenAIModel(model_name='gpt-4o-mini')
}}3. 实现编排器(Orchestrator)方法
借助LLM将输入任务拆分成多个可以同时开展的子任务:
async def orchestrate(task: str) -> OrchestratorResponse:
"""通过分解任务来处理任务。"""
# 创建编排代理
orchestrator_agent = Agent(
config['orchestrator']['model'],
system_prompt=config['orchestrator']['system_prompt'],
result_type=OrchestratorResponse,
)
# 运行编排代理
orchestrator_response = await orchestrator_agent.run(task)
analysis = orchestrator_response.data.analysis
tasks = orchestrator_response.data.tasks
print(colored('分析:', 'cyan'))
print(colored(analysis, 'yellow'))
print(colored('任务列表:', 'cyan'))
for idx, task in enumerate(tasks, 1):
print(colored(f'子任务 {idx}:', 'green'))
pprint.pprint(task.model_dump())
print('\n')
return tasks4. 实现工作器(Worker)方法
# 异步工作函数
async def execute_tasks(task:str,tasks: List[Task]):
"""并行运行子任务并收集结果。"""
# 创建工作代理
worker_agent = Agent(
config['worker']['model'],
system_prompt=config['worker']['system_prompt'],
)
# 并行运行子任务
worker_responses = await asyncio.gather(*[
worker_agent.run(json.dumps({
'original_task': task,
'task_info': task_info.model_dump()
}))
for task_info in tasks
])
# 打印每个任务的结果
for task, response in zip(tasks, worker_responses):
print(f"工作结果 ({task.type}): {response.data}\n")5. 任务测试
现在用一个简单的输入任务做测试:
# 主函数入口
if __name__ == "__main__":
task = '用多种语言风格创建一句2025的新春祝福语。'
sub_tasks = asyncio.run(orchestrate(task))
asyncio.run(execute_tasks(task,sub_tasks))输出的信息中可以观察到任务被拆分成4个不同的子任务:

这些子任务由Worker调用LLM完成并输出:

以上就是Orchestrator-workers模式的基本实现。
由于这里只是简单的内容生成任务,而且下游的Worker也是动态创建的通用LLM调用,因此处理过程相对简单。在实际应用中,也可能有一些更复杂的考虑,比如:是否可以给Workers划分多个任务角色,每个Worker角色可能有不同的提示与“工作职责”,这时候Orchestrator就需要参考Worker的信息来决定子任务如何分解,而且,分解后的子任务就需要根据任务类型创建对应职责的Worker来完成。
下篇我们将一起来看最后一种基础模式:评估器-优化器模式,即反思模式。
end
福利时间
为了帮助LLM开发人员更系统性与更深入的学习RAG应用,特别是企业级的RAG应用场景下,当前主流的优化方法与技术实现,我们编写了《基于大模型的RAG应用开发与优化 — 构建企业级LLM应用》这本长达500页的开发指南,与大家一起来深入到LLM应用开发的全新世界。
更多细节,点击如下链接了解
