
上一篇中我们解析了Anthropic的最新文章《Build effective agents》中的五种Agent Workflows的基础模式,并尝试用轻量级的PydanticAI框架实现。本片将继续实现其中的路由(Route)模式与并行(Parallelization)模式。


回顾请翻阅:

*
路由模式

这是在LLM应用中常见的一种模式。比如在RAG应用中,使用语义路由将查询问题分流到到不同的检索与生成分支:
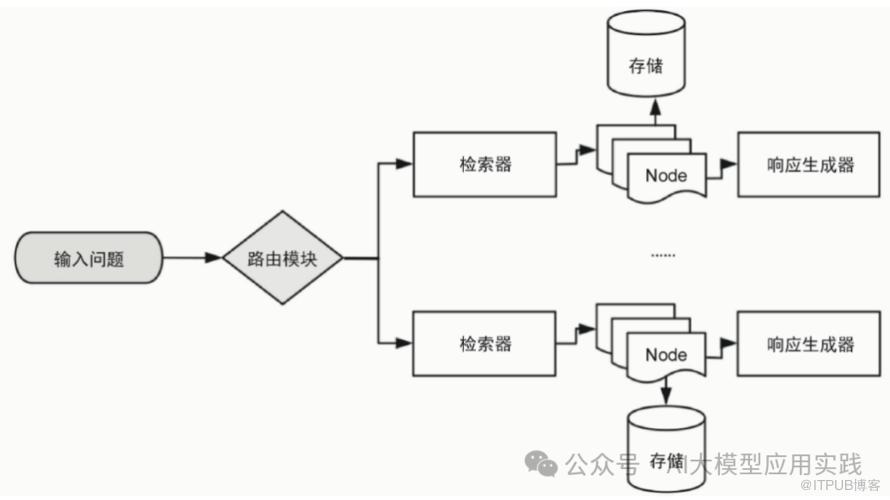
路由模式常见的应用场景有:
智能客服系统自动路由问题到不同模块
Agentic RAG中的请求路由到不同知识库查询
-
多智能体系统将任务路由给不同的智能体完整
一个带有路由的系统至少要包含两个部分:
选择器:一般借助LLM来完成。即由LLM根据提示的信息推理出正确的选项分支。
-
多个选项:这是提供给选择器的多个可选项。在这里的基础模式中,可选项就是多个“增强LLM”调用;而真实LLM应用中的可选项甚至可能是后端的检索器、RAG引擎或者智能体。
现在我们使用PydanticAI来实现这个模式。这个演示的业务场景如下:
路由将用户问题路由给不同的团队来回答,包括售前咨询、售后服务、以及处理其他问题的团队。
1. 为了方便处理与跟踪,首先定义一个选择器输出的结构化类型(自动的类型校验与转换是PydanticAI最吸引人的特性):
...
class RouteSelection(BaseModel):
reasoning: str = Field(..., description=(
'简要解释为什么问题应该被路由到特定团队。考虑关键术语、用户意图和紧急程度。'
))
selection: str = Field(..., description='选择的团队名称')2. 实现核心的任务逻辑,输入参数:用户问题(input)与可选项(routes):
......
async def route(input: str, routes: Dict[str, Dict[str, str]]) -> str:
"""使用内容分类将输入路由到专门的提示。"""
# 首先, 使用链式思维的LLM确定适当的路由
print(f"可用路由: {list(routes.keys())}")
#路由LLM
routing_agent = Agent(
model,
system_prompt=(
'分析输入问题, 并从以下的选项中选择最合适的支持团队:'
'选项包括:\n' + "\n".join([f"{key}: {route['prompt']}" for key, route in routes.items()]) + '\n'
),
result_type=RouteSelection,
)
route_response = await routing_agent.run(input)
reasoning = route_response.data.reasoning
route_key = route_response.data.selection.strip().lower()
print(reasoning)
print(f"选择的路由: {route_key}")
# 使用选定的团队,用专门提示处理输入任务
selected_route = routes[route_key]
worker_agent = Agent(
model=selected_route['model'],
system_prompt=selected_route['prompt'],
tools=selected_route.get('tools', [])
)
return (await worker_agent.run(input)).data3. 测试路由模式。这里输入3个问题,观察问题的路由与执行。与上一个模式一样,为了增加灵活性,我们允许给每个路由分支配置不同的模型(model)与工具(tools,可自行用函数模拟):
support_routes = {
"consult": {
"name": "售前咨询",
"prompt": """您是售前咨询专家。回答有关产品信息的咨询, 请保持专业但友好的回应。请始终以"产品咨询回复:"开头。使用工具以获取产品信息。""",
"model": OpenAIModel(model_name='gpt-4o-mini'),
"tools": [tool_query_productinfo]
},
"service": {
"name": "售后支持",
"prompt": """您是售后服务专家。回答有关产品使用过程中遇到的问题, 请保持专业但友好的回应。请始终以"售后服务回复:"开头。""",
"model": OpenAIModel(model_name='gpt-4o-mini'),
"tools": []
},
"others": {
"name": "人工服务",
"prompt": """你是一位模拟人工服务的支持代表。回复除售前咨询与售后支持以外的问题。请始终以“人工支持回复:”开头。使用搜索工具获取辅助信息。""",
"model": OpenAIModel(model_name='gpt-4o-mini'),
"tools": [tool_search]
},
}
# 测试不同的输入问题
questions = [
"iPhone17什么时候推出?售价多少?",
"使用贵公司手机时经常出现自动重启, 怎么办?",
"小米汽车的最新消息有吗?",
]
async def process_questions():
print("Processing support tickets...\n")
for i, question in enumerate(questions, 1):
print(f"\n-----------------------------\nQuestion {i}: {question}\n")
response = await route(question, support_routes)
print(f"\nResponse {i}:{response}\n")
asyncio.run(process_questions())观测输出,可以看到正确的路由结果以及推理原因;最后由选定的“团队”成功处理了问题并给出了响应:

以上是基础的路由模式实现。注意其特点是:
借助LLM实现语义路由
-
通常只会路由到一个选项分支,并由该分支输出结果。这也是与后面的编排者-工作者模式的最重要区别。
*
并行模式

并行模式顾名思义就是一个任务可以同时由多个“增强LLM”执行,最后汇聚结果并输出:
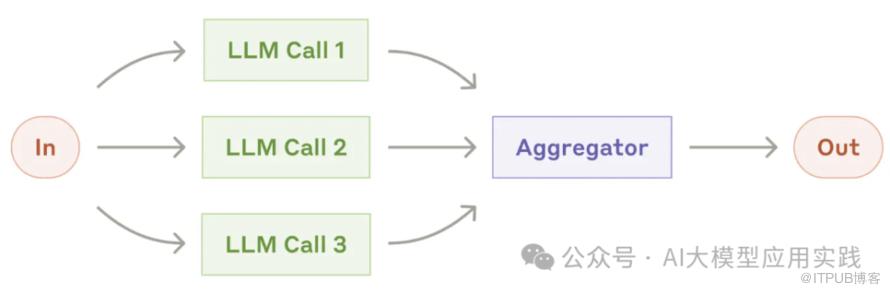
实际应用中有两种情况:
将一个任务拆分成多个子任务同时执行,最后汇总输出。
这个形式中并行的目的是通过任务的拆分与并行提高整体响应速度。如:
将长文翻译任务按段落拆分后并行
-
不同角度的观点分析并行,最后合并
多个LLM同时执行相同任务,最后通过决策机制筛选结果。
这种并行的意义在于获得多个任务结果后进行筛选评比,以提高质量。如:
为某个广告创意文案生成多个备选后选择最佳候选
-
文章翻译生成多个不同版本译文后进行做交叉验证
所以并行模式的特点与要求是:
多个任务(大于1个)可以预先设定
-
多个任务之间不能存在前后依赖关系
并行任务的实现是比较简单的,只需要事先拆分好任务,设定好每个任务的模型、提示与输入,同时调用LLM并汇聚响应结果。
简单的并行任务实现如下(输入系统提示与任务列表):
...
async def parallel(system_prompt,tasks: List[Dict]) -> List[str]:
"""并行处理多个任务,每个任务可以使用自己的工具、输入和模型。"""
async def run_task(task: Dict) -> str:
model = task.get('model', OpenAIModel(model_name='gpt-4o-mini'))
input_data = task['input']
agent = Agent(model, system_prompt=system_prompt)
result = await agent.run(input_data)
return result.data
results = await asyncio.gather(*[
run_task(task)
for task in tasks
])
return results现在可以利用这个算法来完成任务,如:
tasks = [
{
'input': """客户:
- 价格敏感
- 希望更好的技术
- 环保关注""",
'model': OpenAIModel(model_name='gpt-4o-mini')
},
{
'input': """员工:
- 工作安全担忧
- 需要新技能
- 希望明确方向""",
'model': OpenAIModel(model_name='gpt-4o-mini')
},
{
'input': """投资者:
- 期望增长
- 希望成本控制
- 风险关注""",
'model': OpenAIModel(model_name='gpt-4o-mini')
}
]
async def main():
system_prompt = """分析市场变化将如何影响这个利益相关者群体。
提供具体的影响和推荐的行动。
使用清晰的部分和优先级进行格式化。"""
impact_results = await parallel(system_prompt,tasks)
for task, result in zip(tasks, impact_results):
print(f'{result}:{task["input"].split(":")[0]}')
asyncio.run(main())当然,这里只是对结果进行了简单的汇总。如果你需要对任务的多个结果引入决策机制,比如投票,则还需要实现相应的汇聚算法,甚至需要借助LLM。
下篇我们将继续实现另外两种相对复杂的模式:编排者-工作者模式与评估器-优化器模式,请继续关注。
end
福利时间
为了帮助LLM开发人员更系统性与更深入的学习RAG应用,特别是企业级的RAG应用场景下,当前主流的优化方法与技术实现,我们编写了《基于大模型的RAG应用开发与优化 — 构建企业级LLM应用》这本长达500页的开发指南,与大家一起来深入到LLM应用开发的全新世界。
更多细节,点击如下链接了解
现在购,享50%折扣
