生成式AI在企业落地的过程中,通常我们更多的关注在模型、工具、RAG等应用本身,却往往忽视了数据这一重要基石。没有完善与高质量的数据支撑是导致很多生成式AI应用失败的关键之一,忽视数据的治理而过度追求模型能力或应用优化很可能是事倍功半的结果。
今天和大家分享来自Monte Carlo公司发布的2024年企业生成式AI应用过程中数据有关的一些调查结论,我们摘取其中有参考与启示意义的结果来简单解读。
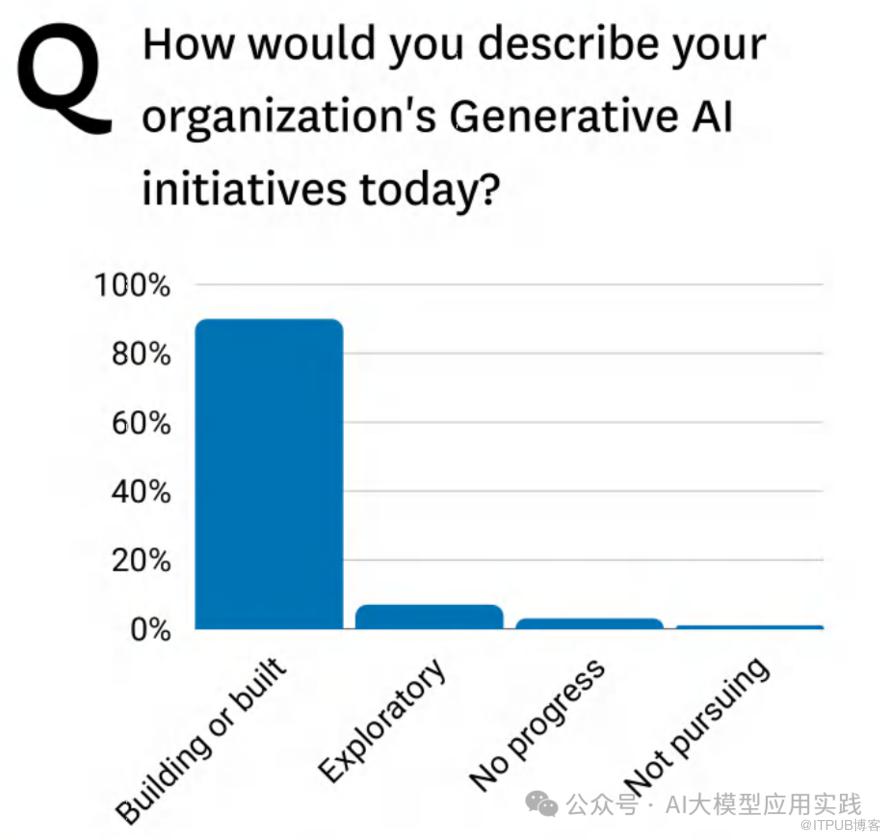
调查结果:
• 90% 的企业正在构建或已经构建某种形式的AI产品。
• 只有极少数企业处于探索阶段(Exploratory)或没有进展(No progress),几乎没有企业表示不打算开展AI项目(Not pursuing)。
解读:
• 生成式AI在各行业中的应用广泛,几乎成为企业技术发展的标配。
• 数据团队和管理层都致力于加速AI项目落地,以应对市场和业务需求。
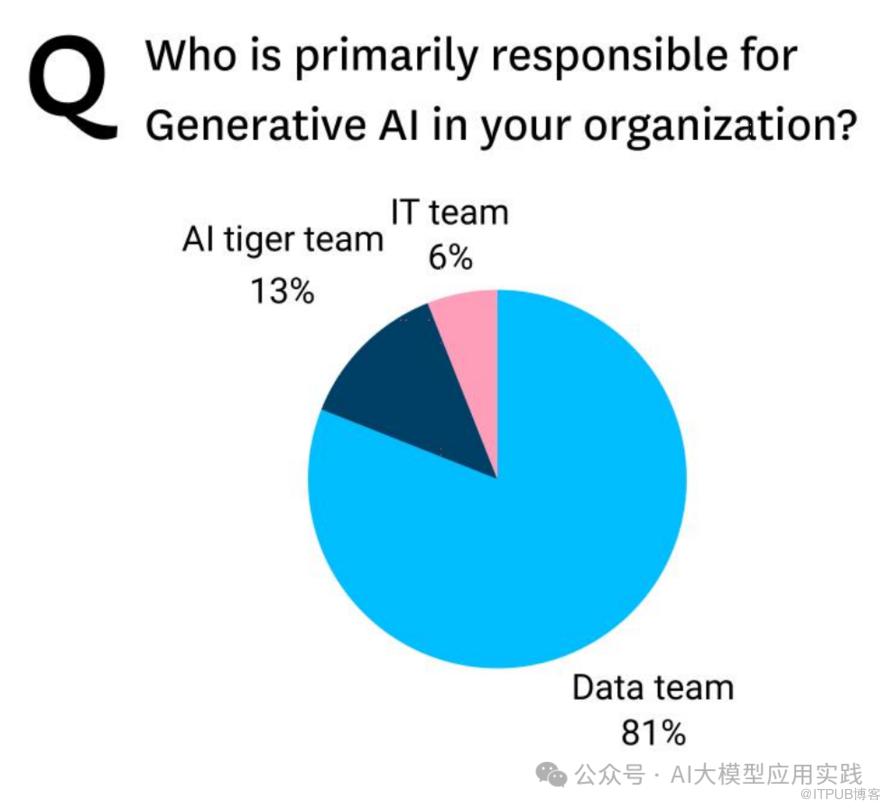
调查结果:
• 数据团队(Data team):占 81%,是组织中主要负责生成式AI的部门。
• AI Tiger Team:占 13%,通常是专门为AI任务组建的精英团队。
• IT团队(IT Team):仅占 6%,表明IT团队更多负责技术基础设施,而非直接的AI应用开发。
解读:
• 数据团队被视为AI项目的核心,因其在数据管理和分析方面的专业知识。
• 专门的AI Tiger Team尽管人数较少,但往往负责推动创新性或战略性AI项目。
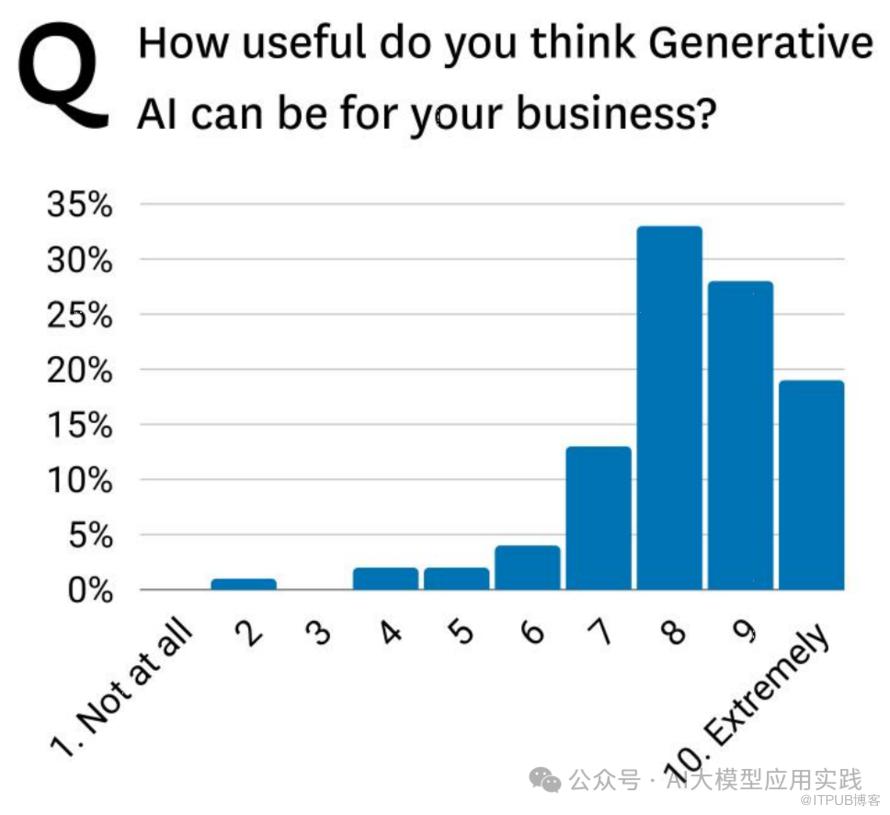
调查结果:
• 82% 的受访者对生成式AI的有用性评分在 8分或以上。
• 高分集中:大部分评分为 8-10,其中 9分和10分占主要比例。
• 低分稀少:几乎没有人认为生成式AI“完全没用”(评分1或2)。
解读:
• 数据团队普遍认为生成式AI对业务是有用的,并非空有“炒作”。
• 但它的实际价值需要依赖于正确的用例和高质量的数据。

调查结果:
数据团队在实现生成式AI时,采取了多种策略,主要包括:
• 使用MaaS(Model as a Service,例如OpenAI等):49%
• 构建自有LLM(Large Language Model):49%
• 微调(Fine-tuning):48%
• RAG(检索增强生成):48%
解读:
• 各种策略的采用比例非常接近,表明不同组织根据自身资源和目标选择了不同的路径。
• MaaS和自建LLM的比例相当,显示出组织在使用外部工具和构建内部能力之间存在均衡。
• 微调和RAG技术的流行表明,数据团队希望提高生成式AI的业务相关性和准确性。
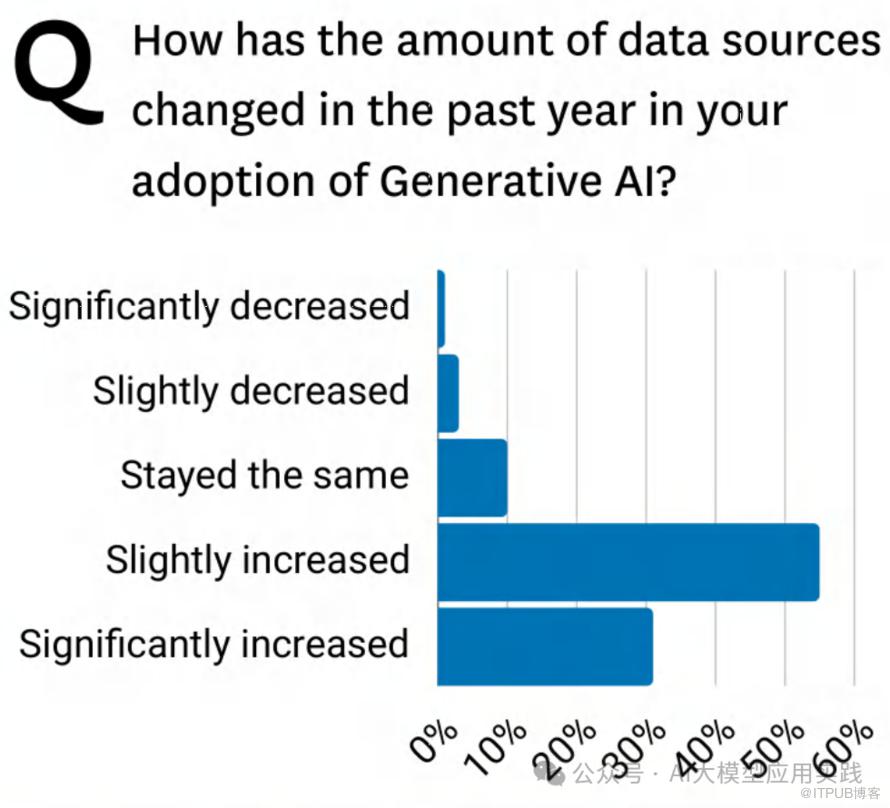
调查数据:
• 略微增加(Slightly increased):占 50% 左右,是最常见的变化。
• 显著增加(Significantly increased):接近 30%,表明部分企业的数据源大幅增长。
• 保持不变(Stayed the same):不到 15%。
• 数据源减少(Slightly/Significantly decreased)几乎没有出现。
解读:
• 大多数企业在采用生成式AI后,数据源数量有所增加。
• 数据源的增加使企业能够支持更多新用例,但同时也增加了数据管理的复杂性。
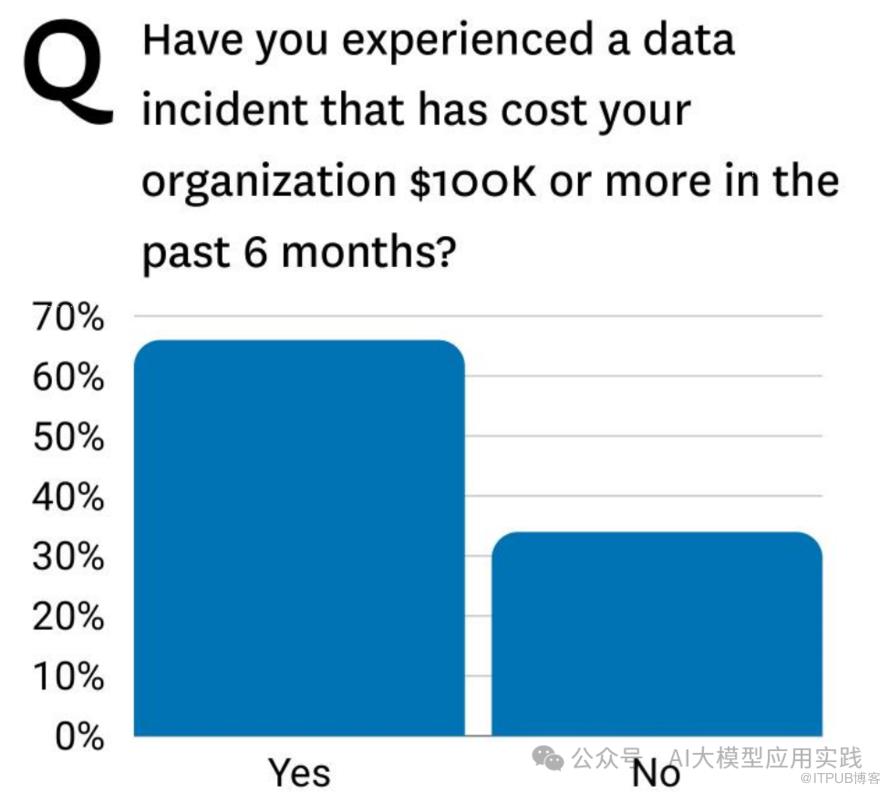
调查结果:
• 超过 60% 的受访者表示,在过去6个月内,他们的企业经历了因数据问题导致的事故,经济损失超过 10万美元。
• 少数 不到40% 的受访者表示没有经历类似事件。
解读:
• 数据质量问题是企业的重大隐患,尤其在生成式AI广泛应用的背景下,错误或低质量数据可能导致严重的财务损失和错误决策。
• 劣质数据成本高昂,企业必须重视并采取措施改善数据质量。
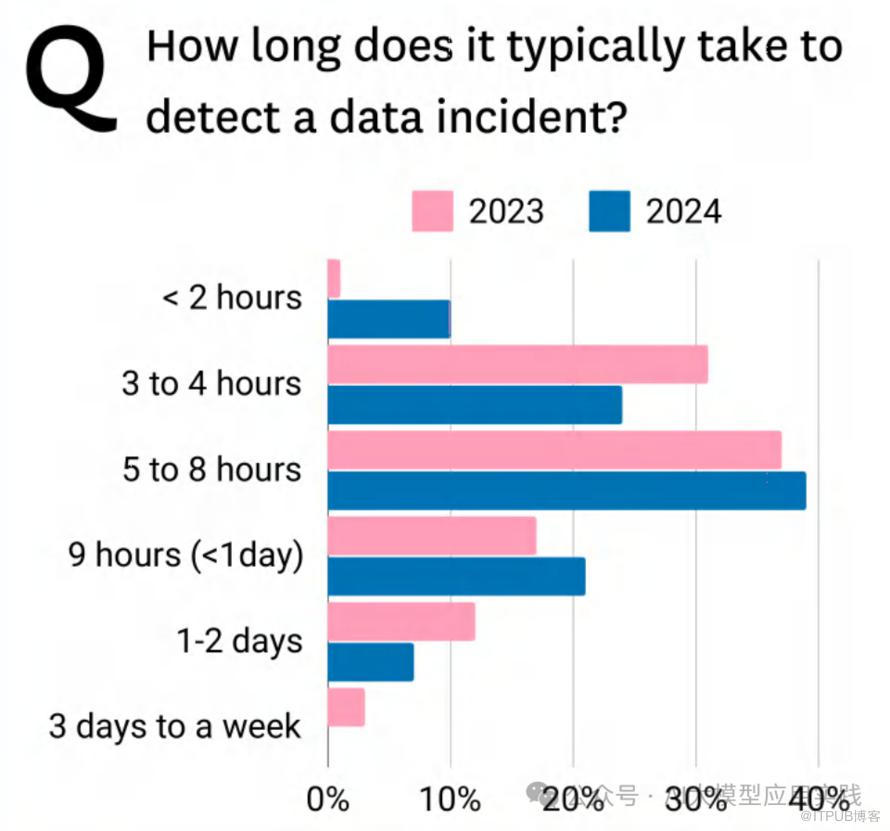
调查结果:
比较了 2023 年和 2024 年检测数据事件所需时间的变化:
• 2023年:大多数数据事件检测时间集中在 5-8小时 和 9小时到1天。
• 2024年:显著改善,更多事件在 3-4小时 和 <2小时 内被检测到。
解读:
• 数据团队在过去一年中显著缩短了检测数据事件的时间,但仍有部分事件超过1天才被发现。
• 更快的检测时间有助于降低数据中断的影响和相关成本。
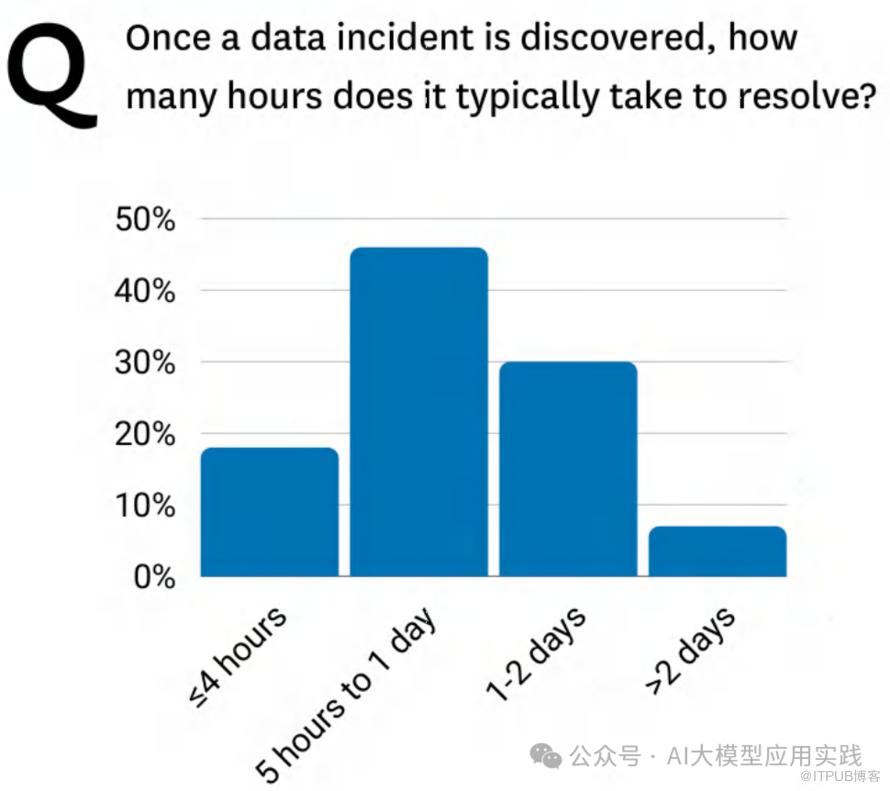
调查结果:
• 一次数据事件的平均停机时间(检测 + 解决)通常为 8小时。
• 约 37% 的受访者表示,仅解决问题就需要 1天或更长时间。
解读:
• 数据质量问题的复杂性不断增加,尤其是在AI驱动的数据系统中,停机时间成为企业的重要成本。
• 如果不能快速解决问题,企业将面对不断积累的负面影响,包括客户信任下降和运营效率受阻。
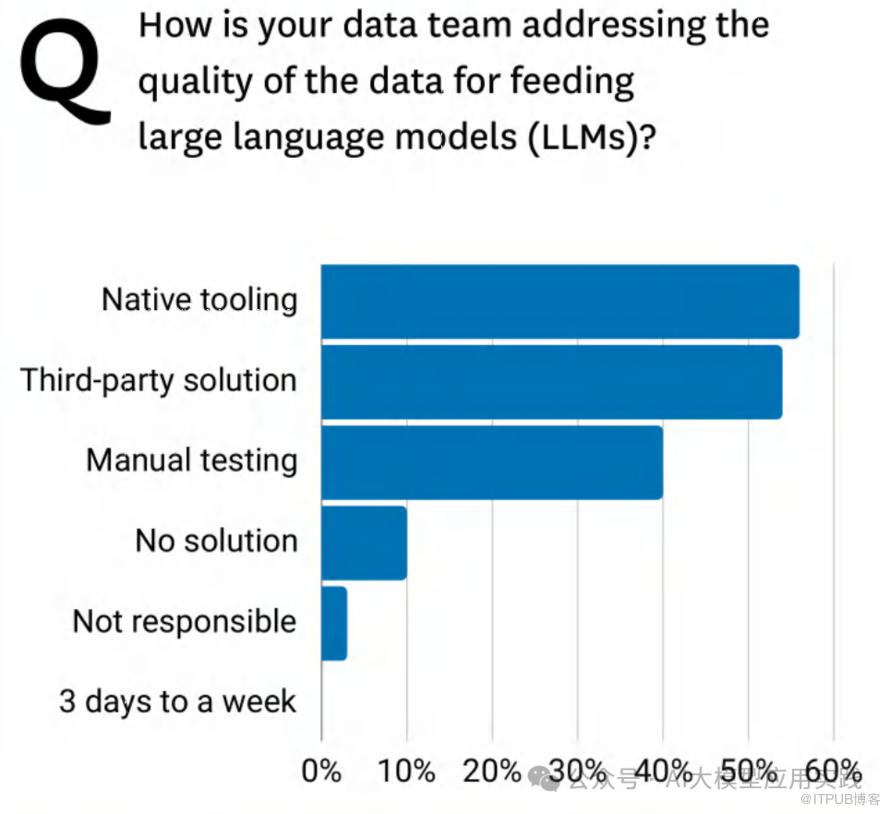
调查结果:
数据团队在管理数据质量时采用的主要方法包括:
• 原生工具(Native tooling):使用率最高,接近 50%,显示企业越来越倾向于依赖内部工具。
• 第三方解决方案(Third-party solution):约 40%,表明部分企业使用外部服务来补充数据治理能力。
• 手动测试(Manual testing):仍占 30%,显示许多团队依赖传统、低效的方法。
• 无解决方案(No solution):约 10% 的团队尚未采取任何措施解决数据质量问题。
• 无责任方(Not responsible):极少团队认为数据质量管理与自身无关。
解读:
• 手动测试的广泛使用表明许多团队仍缺乏自动化和现代化工具。
• 超过半数的团队依赖于低效方法,表明数据治理在生成式AI环境中仍有显著改进空间。

以上是报告中的核心内容。
我们认为,生成式AI的价值不容忽视,但高质量数据是其发挥价值的基础。企业需要在数据治理、数据质量管理和适配生成式AI的场景中(如RAG与微调)投入更多资源,以确保生成式AI技术能够可靠、高效地支持业务增长。
end
福利时间
为了帮助LLM开发人员更系统性与更深入的学习RAG应用,特别是企业级的RAG应用场景下,当前主流的优化方法与技术实现,我们编写了《基于大模型的RAG应用开发与优化 — 构建企业级LLM应用》这本长达500页的开发指南,与大家一起来深入到LLM应用开发的全新世界。
更多细节,点击如下链接了解
此处购买享50%折扣
