Hi
点击上方蓝字关注我们

多模态文档处理

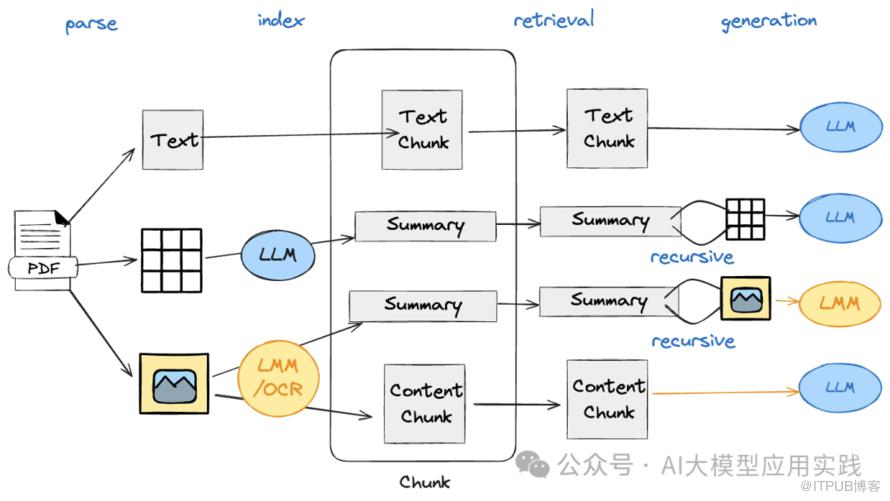
以最常见的复杂PDF处理为例:
【文本】:按照普通文本知识相同的方法做向量嵌入与检索。 【表格】:直接对Table的文本内容做嵌入通常检索效果欠佳,可以借助大模型(LLM)生成表格内容描述与摘要用于嵌入与检索(比如下图)。这有利于提高检索精准度及LLM对表格内容的理解。在检索阶段,需要关联检索出原始的Table内容用于后续生成。

【图片】:借助多模态视觉大模型比如qwen-vl,gpt-4v结合OCR技术对图片进行理解是常见的方法。还可进一步分为两种处理情况:

文档解析

Unstructured:强大的非结构化数据处理平台与工具,提供商业在线API服务与开源SDK两种使用方式。支持复杂文档如PDF/PPT/DOC等的高效解析与处理,包括清理、语义分割、提取实体等。缺点是较为复杂,类似的还有OmniParse开源平台。

LlamaParse:这是著名的LLM开发框架LlamaIndex提供的在线文档解析服务,主要提供复杂PDF文档的在线解析与提取,其最大优势是与LlamaIndex有极好的集成,比如可以借助模型在提取时自动生成表格的摘要信息。缺点是必须在线使用。 Open-Parse:一个相对轻量级的复杂文档分块与提取的开源库。支持语义分块与OCR,简单易用,且支持与LlamaIndex框架的集成,比如将提取的文档直接转化为LlamaIndex中的Node。 此外,国内开源的RAG引擎平台RAGFlow内置了很强的深度文档理解能力,(但未开放文档解析的独立API),如果你需要构建基于深度文档解析的在线RAG引擎,可以考虑尝试。

多模态模型 & OCR

一种是借助具备OCR能力的多模态模型比如qwen-vl -
一种是借助专业的OCR模型与工具库。比如上面的unstructured、ominiparse都可以在加载语言的模块后具备OCR识别能力

关联检索

LangChain:可借助多向量存储与检索(MultiVectorRetriever)来实现,将存储向量的VectorStore与图片存储做关键存储与检索 -
LlamaIndex:可借助构建递归检索器(RecursiveRetriever)来实现,将存储文本向量的Node指向存储原始表格内容或图片的Node

高级检索与查询重写


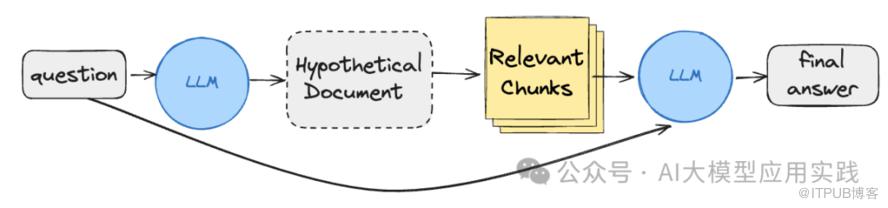
HyDE重写

根据输入问题,生成一个假设性的答案。注意,这个答案来自LLM本身的知识,可能包含错误或者不够准确。 对该假设性的答案进行嵌入,并检索出具有相似向量的知识块(可以同时携带原问题)。 用检索出的知识块和原问题借助LLM生成最终答案。

分步问题重写

分解出第一个问题:“2022年世界杯冠军球队是哪个国家队?”,然后首先查询出该问题的答案。 根据原问题以及之前的推理过程,分解出第二个问题:“2022年世界杯阿根廷国家队球员有哪些球员?” -
对分解出的第二个问题进行查询,并得出最终答案。


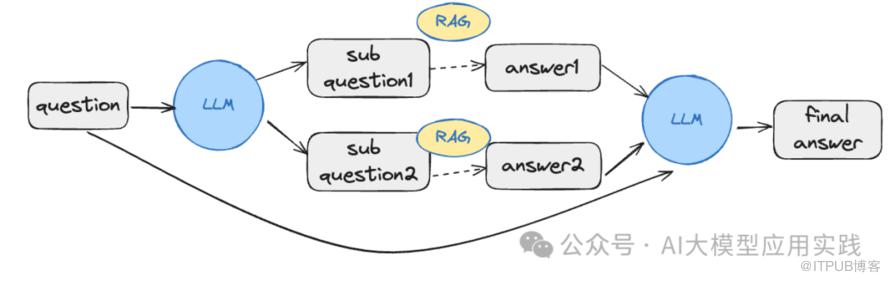
子问题重写

将输入问题借助LLM生成多个相关的子问题,这些子问题可以是LLM自身可以回答,也可以是借助某个已有的RAG引擎能够回答。 对多个子问题进行查询,通过检索生成,得出子问题的答案。 -
根据多个子问题的答案与原问题,推理并合成,输出最终问题答案。

后退问题重写

借助LLM将原问题解释为一个更通用的后退问题。比如原问题是“Joe出生在哪个国家?在哪里度过了他的童年”。生成的后退问题可能是“Joe的生平经历有哪些”。 对重写的后退问题进行RAG检索与生成,获得相关的知识内容与答案。 将重写问题的生成答案、原问题输入(也可结合原问题检索的相关知识)再次通过LLM进行生成,输出最终答案。


RAG应用评估

需要衡量大模型输出不确定性的影响。 LLM应用在持续演进中的能力改进评估。 定期评估与了解知识库变化带来的影响与干扰。 -
评估大模型或嵌入模型的选择,以及版本的影响。

评估依据与指标

输入问题(question):即用户在使用RAG 应用时的输入问题。 响应结果(answer):RAG应用的最终输出,即问题的答案。 上下文(contexts):用来增强RAG应用输出的参考上下文。 -
事实依据(reference_answer):真实的正确答案,通常需要人类标注。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

RAG评估技术

LlamaIndex的Evaluation模块,内置了检索与生成阶段的各指标评估器。 -
Langchain的LangSmith平台,有完善的评估数据集管理与批量评估方案。
RAGAS评估框架(可参考:如何科学评估RAG应用?基于大模型的RAG应用中的四个常见问题及方案探讨【下】) -
LangFuse:一个类似LangSmith的开源大模型应用工程化平台

END
