
点击上方


让我们简单回顾LangGraph:
LangGraph从LangChain最近的0.1版本开始引入,用于开发更强大的AI Agent的库。
LangGraph诞生的目的是为了解决LLM应用中的复杂“循环”问题与Agent开发过于“黑盒化”的问题。
LangGraph把一个Single-Agent或者Multi-Agent系统用Graph来表示,从而能够支持最复杂的任务节点与关系。
-
LangGraph开发最重要的是定义Graph(包括任务节点Node与边Edge)与状态(state,随着任务执行而变化的状态信息)。
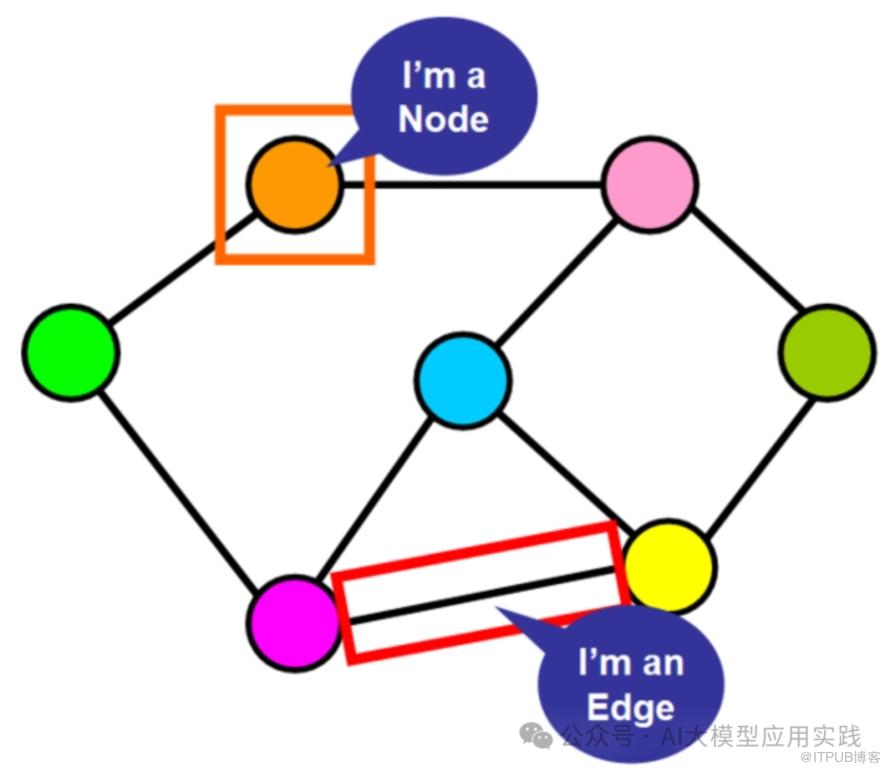
(回顾:彻底搞懂LangGraph:构建强大的Multi-Agent多智能体应用的LangChain新利器 【1】)
从本篇开始,我们会陆续剖析几个我们认为最重要或最有趣的LangGraph应用案例,并尽量确保即使你没有LangChain经验,也能了解到LangGraph的魅力所在。
我们从目前最常见的知识库RAG应用开始。


文中代码部分参考LangChain官方案例进行修改与解读,读者可使用官方提供的Jupyter Notebook自行实验。

PART 01


自纠正的RAG:C-RAG
RAG(检索增强生成)是目前LLM应用领域最为人熟知也相对成熟的一种解决方案,在构建基于私有知识库的LLM应用上表现出了较好的适应性。但做过RAG应用的朋友应该对此深有体会:RAG应用的输出效果在极大的程度上依赖于其中Retrieve这一环节召回的知识文档(也叫知识块)的相关性与精确性,而一些不相关的文档召回甚至可能误导LLM激发“幻觉”问题。(关于RAG应用的知识召回,我们曾经介绍过一些优化方向,具体请阅读文章:深度|基于大模型的RAG应用中的四个常见问题及方案探讨【上】)。
因此,在此基础上有研究者提出了一种“自纠错的RAG”方案(Corrective-RAG,论文参考:https://arxiv.org/pdf/2401.15884.pdf):
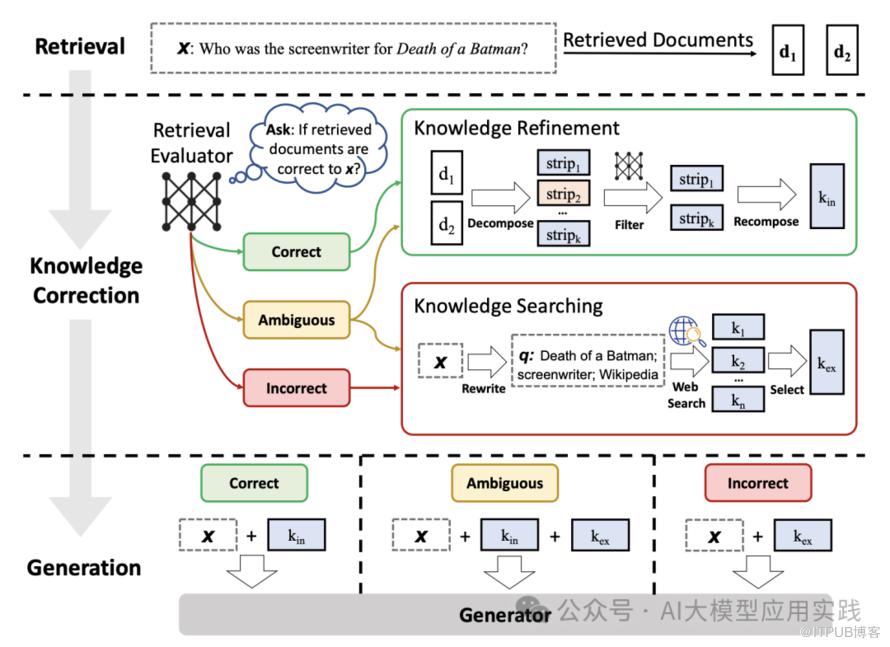
这个图看上去复杂,但C-RAG的核心思想是简洁的:
借助一个轻量级的评估器(通常也是借助LLM),评估召回的相关文档质量,将其分为相关、存疑、不相关,并根据评估结果做相应的后续优化:
【针对相关文档】
如果至少有一个检索文档是相关的,则该文档会交给LLM用来生成
-
在LLM生成答案之前,还将对知识细化;并进一步过滤无关的部分
【针对存疑/不相关文档】
使用网络搜索或其他方式寻找相关知识文档来做补充
-
在通过其他途径寻求补充知识之前对输入问题做重写(Re-write)
简而言之,C-RAG就是通过对检索出的文档做关联性评估,去除不相关的知识文档,并尝试借助其他途径补充相关知识,从而提高输入的关联知识(即LLM回答问题时需要参考的上下文)质量,让回答更准确。
PART 02


LangGraph实现C-RAG的关键设计
如前文所说,用LangGraph实现一个LLM应用,在开始前,你需要设计好这个应用的“工作流程图”,也就是“Graph”;以及在工作过程中的“状态”信息,也就是“State”。
【Graph设计】
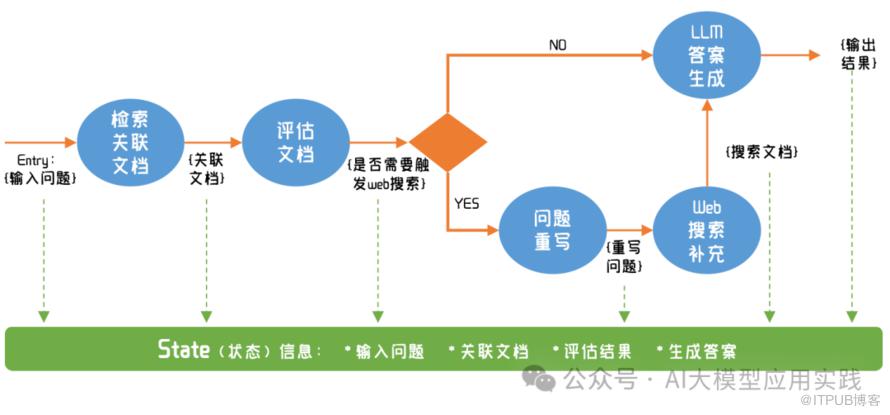
如我们日常在软件编码时的简单流程图类似,Graph其实代表了LLM应用在接收到一个输入时的处理流程。在这里的C-RAG的应用中,首先考虑其存在哪些任务节点(Node),节点通常代表一个可以执行的、相对独立的流程动作,在技术上可以是一个可运行的Chain、Agent或者一个函数。这里设计如下任务节点:
-
检索关联文档(retrieve)
从向量库中根据输入问题搜索语义相近的知识文档
-
文档关联性评估(grade_documents)
对搜索出的知识文档进行量化评估其关联性
-
大模型生成答案(generate)
将问题与关联的知识文档交给LLM学习并生成答案
-
输入问题重写(transform_query)
当retrieve的知识文档不相关时,对输入问题进行改写
Web搜索(web_search)
借助在线Web搜索来补充关联知识文档


为了简化处理过程,此处不考虑原论文中对关联的知识文档进一步的细化(strip)、过滤与重组动作。

因此可以定义如下的Graph,来实现一个基本的C-RAG应用:
【State设计】
LangGraph中需要定义的State,用来在每个节点动作之间保存与传递必须的信息。这样每个节点有State这个统一的数据访问对象,这里我们把任务过程中的以下信息保存到State:
question:输入问题,或者改写后的问题
documents:所有检索或web搜索的关联知识文档
run_web_search:文档评估结果,确定是否需要Web搜索
generation:LLM最后生成的输出答案
定义如下的State,用Dict字典对象来保存这些信息即可:
class GraphState(TypedDict):
keys: Dict[str, any]PART 03


代码实现与测试
设计完Graph与State以后,剩下的任务是用代码来实现Graph中的各个节点(Node)并定义节点间的关系(Edge),这里我们简单描述与解释示例代码。如果你有过RAG的初步经验,理解起来应该不困难。
Node:检索关联文档
案例中我们用百度最新产品Comate的两篇在线文档构建一个简单私有知识库,并做拆分与嵌入,构建向量存储。这部分过程与普通RAG应用一样,此处不做介绍。完成后就可以创建retrieve这个节点(注意节点的输入输出就是State):
def retrieve(state):
'''
从state中取出问题 => 调用检索器获取相关文档
把获取的文档添加到state中,并返回新的状态即可
'''
state_dict = state["keys"]
question = state_dict["question"]
documents = retriever.get_relevant_documents(question)
return {"keys": {"documents": documents, "question": question}}Node:文档关联性评估
这个节点构建一个轻量级的文档相关性评估工具,调用这个工具可以对召回的文档做评估,得出结论:
def grade_documents(state):
#取出state中的问题和检索的文档
print("---CHECK RELEVANCE---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
#此处省略定义llm_with_tool/parser_tool工具,可参考langchain文档
#Prompt提示模版
prompt = PromptTemplate(
template="""您是一个评分人员,评估检索到的文档与用户问题
的相关性。以下是检索到的文档:
{context}
以下是用户的问题:{question}
如果文档包含与用户问题相关的关键词或语义意义,请将其评为相关。给出一个yes或no来表明文档是否与问题相关。""",
input_variables=["context", "question"],
)
#构建一个评估的Chain
chain = prompt | llm_with_tool | parser_tool
#对文档做评估
filtered_docs = []
search = "No"
for d in documents:
score = chain.invoke({"question": question, "context": d.page_content})
grade = score[0].binary_score
#如果相关,则添加到关联文档
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
#如果不相关,则要求进行web搜索
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
search = "Yes" # Perform web search
continue
#将过滤后的文档、是否需要web搜索保存到state返回
return {
"keys": {
"documents": filtered_docs,
"question": question,
"run_web_search": search,
}
}Node:LLM生成答案
这部分非常简单,即把问题和关联知识丢给LLM生成答案:
def generate(state):
print("---GENERATE---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
# 获取一个现成的Prompt(借助langchain hub)
prompt = hub.pull("rlm/rag-prompt")
# 模型
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0, streaming=True)
#Chain:提示词=>llm=>输出解析
rag_chain = prompt | llm | StrOutputParser()
#调用
generation = rag_chain.invoke({"context": documents, "question": question})
#结果放入state,返回
return {
"keys": {"documents": documents, "question": question, "generation": generation}
}Node:输入问题重写
这个节点是在发现召回的文档相关性不够时,使用LLM优化输入问题:
def transform_query(state):、
print("---TRANSFORM QUERY---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
#提示模版
prompt = PromptTemplate(
template="""你需要生成针对检索优化的问题。请根据输入内容,尝试推理其中的语义意图/含义。这是初始问题:
{question}
请提出一个改进的问题:""",
input_variables=["question"],
)
# 模型
model = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-1106", streaming=True)
# 链
chain = prompt | model | StrOutputParser()
# 调用获得改进的问题
better_question = chain.invoke({"question": question})
# 放入state返回
return {"keys": {"documents": documents, "question": better_question}}Node:Web搜索
这个节点我们借助Bing搜索,来搜索问题的网络相关知识:
def web_search(state):
print("---WEB SEARCH---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
#bing搜索
tool = BingSearchAPIWrapper(k=3)
docs = tool.run(question)
web_results = "\n".join([d for d in docs])
web_results = Document(page_content=web_results)
#搜索结果添加到已经有的documents后面返回
documents.append(web_results)
return {"keys": {"documents": documents, "question": question}}其他:辅助方法
上一篇介绍LangGraph的边(edge)时说过,对于条件边,需要有一个辅助判断的函数,用来帮助决定走向哪个节点。这里由于需要根据文档相关性评估的结果来决定是生成答案,还是进行web搜索。因此需要这样一个辅助方法,很好理解:
def decide_to_generate(state):
print("---DECIDE TO GENERATE---")
state_dict = state["keys"]
question = state_dict["question"]
filtered_documents = state_dict["documents"]
#取出评估节点放入的评估结果:是否需要web搜索
search = state_dict["run_web_search"]
#如果需要,返回下一个节点:transform_query
if search == "Yes":
print("---DECISION: TRANSFORM QUERY and RUN WEB SEARCH---")
return "transform_query"
#如果不需要,返回下一个节点:generate
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"构建Graph,创建APP
在节点(node)与辅助函数构建完成后,就可以构建Graph:
#定一个一个Graph
workflow = StateGraph(GraphState)
#添加上面准备的Node
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
workflow.add_node("web_search", web_search) # web search
#特殊边:入口
workflow.set_entry_point("retrieve")
#普通边:检索完成后,进入文档评估
workflow.add_edge("retrieve", "grade_documents")
#条件边:借助辅助方法决定进入哪一个节点
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
#普通边:改写问题后总是去搜索
workflow.add_edge("transform_query", "web_search")
#普通边:搜索后,生成最后答案
workflow.add_edge("web_search", "generate")
#特殊边:生成答案后结束
workflow.add_edge("generate", END)
#编译成应用,完成!
app = workflow.compile()测试APP
1. 我们首先测试一个知识库能够完美回答的问题:
inputs = {"keys": {"question": "百度的comate是什么?有哪些特点?"}}
for output in app.stream(inputs):
#output中保存了每一步节点完成信息,key是节点名,value是state
for key, value in output.items():
pprint.pprint(f"Node '{key}':")
pprint.pprint("\n---\n")
# 打印最后的State中的generation,就是最终答案
pprint.pprint(value["keys"]["generation"])查看输出日志,可以看到这次任务经过了retrieve,grade_documents,generate三个节点,而没有经过web_search,原因是因为召回的文档都相关(document relevant)。
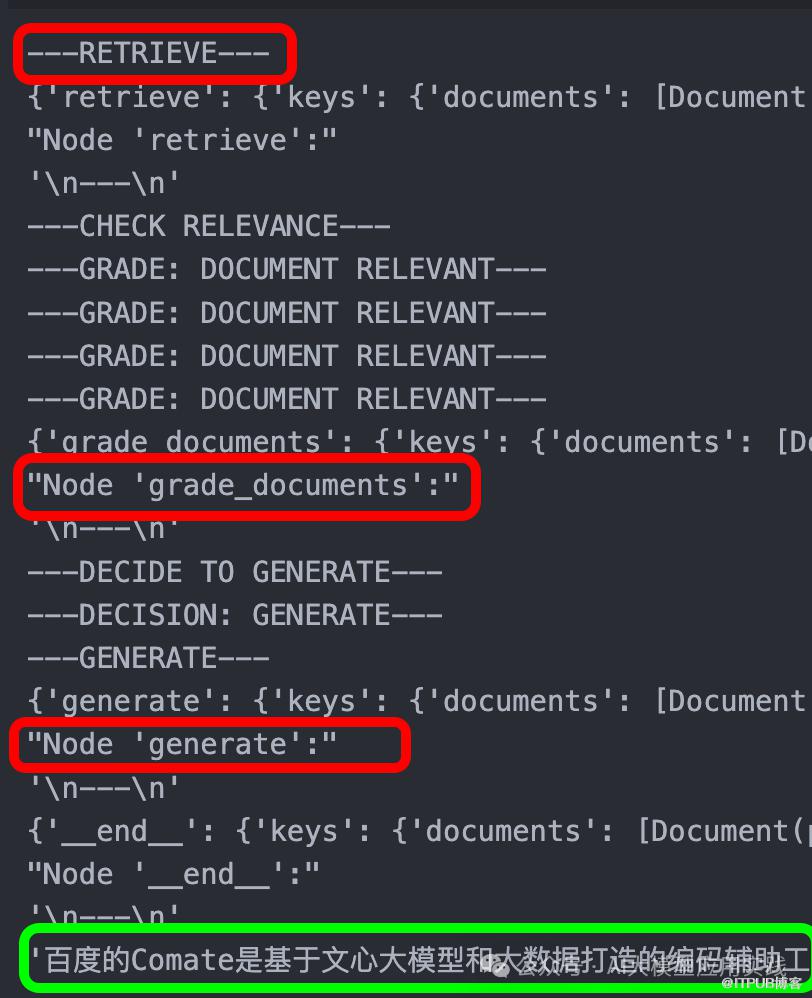
2. 但如果把上面的输入问题换一个知识库无法完全回答的问题,比如:

观察输出日志,可以发现任务多经过了transform_query与web_search两个新的节点,原因是开始召回的知识文档经过评估后,发现无法回答输入问题(NOT RELEVANT),因此需要借助Web搜索来补充知识。

至此,我们就完成了这个基础的C-RAG应用。
PART 04


结束语
以上部分我们用LangGraph来实现了一种优化的RAG方案:通过对召回的关联知识文档进行评估,并根据评估结果去除不相关的干扰知识,同时借助其他手段(改写问题并Web搜索)来补充知识文档,从而让最终结果更准确。在这个例子中,展现了LangGraph在构建复杂LLM应用时的灵活与强大的能力。由于采用Graph这种支持更复杂关系的结构来定义任务过程,也就具备了构建超级AI Agent的底层基础。
后续文章中将继续分享与剖析其他LangGraph使用案例。

END

HAS ARRIVED

点个在看你最好看