注意:本篇文章字数过多 ,建议分时间吸收,因为一次读完我感觉效率没有多次吸收好
前言
在当今数据驱动的世界中,数据库技术已成为每个技术人员必备的核心技能之一。KWDB(Knowledge Worker Database)作为一种新兴的数据库解决方案,因其易用性、灵活性和高性能而受到广泛关注。无论你是刚入门的编程小白、正在寻找实习机会的学生,还是已经从事企业开发的专业人员,掌握KWDB都将为大家的技术栈增添重要的一笔。加油!
本文将从零开始,全面介绍KWDB的基础概念与语法,内容涵盖数据库设计原则、基本操作、高级查询技巧以及实际应用场景。通过系统化的学习路径和丰富的实例演示,我们将逐步建立起对KWDB的深入理解,并能够将其应用于实际项目中。
第一章 KWDB概述
1.1 什么是KWDB( 官网)
KWDB(Knowledge Worker Database)是一款面向 AIoT 场景的分布式多模数据库产品,支持在同一实例同时建立时序库和关系库并融合处理多模数据,具备千万级设备接入、百万级数据秒级写入、亿级数据秒级读取等时序数据高效处理能力,具有稳定安全、高可用、易运维等特点。
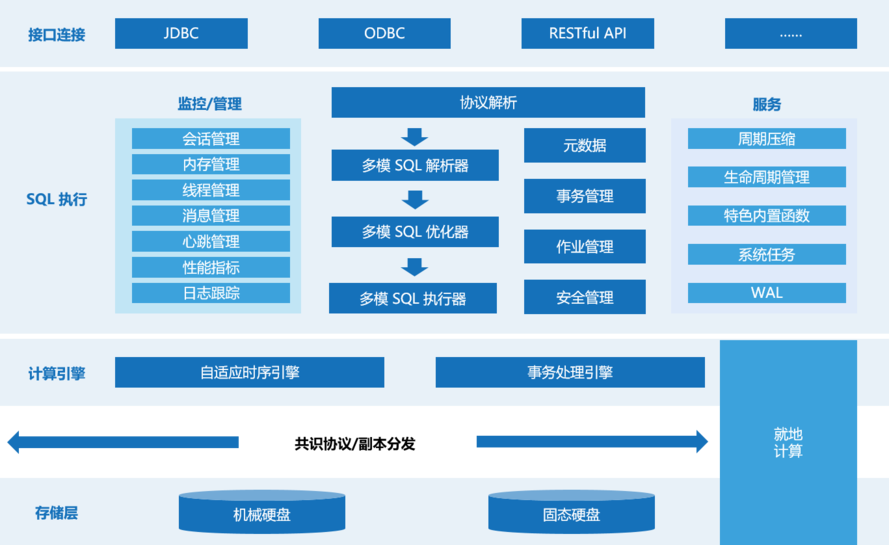
KWDB的设计哲学基于三个核心原则:
-
易用性:语法简洁明了,降低学习曲线
-
可扩展性:从小型应用到企业级系统都能胜任
-
高性能:优化过的查询引擎确保快速响应
与传统数据库相比,KWDB具有以下显著特点:
-
动态模式支持,无需预先严格定义表结构
-
内置JSON处理能力,轻松应对半结构化数据
-
智能查询优化,自动选择最佳执行路径
-
跨平台兼容,支持多种部署环境
1.2 KWDB的常用应用场景
KWDB的灵活性使其适用于广泛的应用场景:
个人开发者和小型项目:
-
移动应用后端数据存储
-
个人网站内容管理
-
小型电商系统
企业级应用:
-
客户关系管理系统(CRM)
-
企业资源规划(ERP)
-
供应链管理系统
数据分析和商业智能:
-
报表生成
-
数据可视化
-
实时分析仪表盘
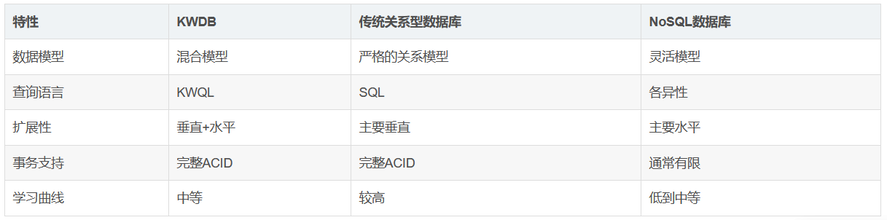
1.3 KWDB与其他数据库的比较
1.4 KWDB的下载(因为gitten写的很好,所以我这里在复述一遍【比心】)

环境准备
1.下载和解压 CMake 安装包。
tar -C /usr/local/ -xvf cmake-3.23.4-linux-x86_64.tar.gz mv /usr/local/cmake-3.23.4-linux-x86_64 /usr/local/cmake
2.下载和解压 Go 安装包。
tar -C /usr/local -xvf go1.22.5.linux-amd64.tar.gz
3.创建用于存放项目代码的代码目录。
mkdir -p /home/go/src/gitee.com
4.设置 Go 和 CMake 的环境变量。
(1)个人用户设置:修改~/.bashrc 文件
(2)系统全局设置(需要 root 权限):修改/etc/profile文件
export GOROOT=/usr/local/go export GOPATH=/home/go #请以实际代码下载存放路径为准,在此以home/go目录为例 export PATH=$PATH:/usr/local/go/bin:/usr/local/cmake/bin
5. 使变量设置立即生效:
(1)个人用户设置:
source ~/.bashrc
(2)系统全局设置:
source /etc/profile
下载代码
在 KWDB 代码仓库下载代码,并将其存储到 GOPATH 声明的目录。

1.使用 git clone 命令:
git clone https://gitee.com/kwdb/kwdb.git /home/go/src/gitee.com/kwbasedb #请勿修改目录路径中的 src/gitee.com/kwbasedb cd /home/go/src/gitee.com/kwbasedb git submodule update --init #适用于首 次拉取代码 git submodule update --remote
2.下载代码压缩包,并将其解压缩到指定目录。
构建和安装
1.在项目目录下创建并切换到构建目录。
cd /home/go/src/gitee.com/kwbasedb mkdir build && cd build
2.运行 CMake 配置。
cmake .. -DCMAKE_BUILD_TYPE= [Release | Debug]
参数说明: CMAKE_BUILD_TYPE:指定构建类型,默认为 Debug。可选值为 Debug 或 Release,首字母需大写。
3.禁用Go模块功能。
(1)设置环境变量
<1>个人用户设置:修改~/.bashrc 文件
<2>系统全局设置(需要 root 权限):修改/etc/profile文件
export GO111MODULE=off
(2)使变量设置立即生效:
<1>个人用户设置:
source ~/.bashrc
<2>系统全局设置:
source /etc/profile
4.编译和安装项目。
提示:
(1)如果编译时出现遗留的 protobuf 自动生成的文件导致报错,可使用make clean 清理编译目录。
(2)如果需要额外指定 protobuf 的文件路径,请使用 make PROTOBUF_DIR=
make make install
编译和安装成功后的文件清单如下:
/home/go/src/gitee.com/kwbasedb ├── install │ ├── bin │ │ ├── err_inject.sh │ │ ├── query_kwbase_status.sh │ │ ├── query_status.sh │ │ ├── setup_cert_file.sh │ │ ├── utils.sh │ │ └── kwbase │ └── lib │ ├── libcommon.so │ └── libkwdbts2.so
5.(可选)进入 kwbase 脚本所在目录,查看数据库版本,验证是否安装成功。
./kwbase version KaiwuDB Version: V2.0.3.2_RC3-3-gfe5eeb853e-dirty Build Time: 2024/07/19 06:24:00 Distribution: Platform: linux amd64 (x86_64-linux-gnu) Go Version: go1.22.5 C Compiler: gcc 11.4.0 Build SHA-1: fe5eeb853e0884a963fd43b380a0b0057f88fb19
启动数据库
1.进入 kwbase 脚本所在目录。
cd /home/go/src/gitee.com/kwbasedb/install/bin
2.设置共享库的搜索路径。
export LD_LIBRARY_PATH=../lib
3.启动数据库。
./kwbase start-single-node --insaecure --listen-addr=:26257 --background
4.数据库启动后即可通过 kwbase CLI 工具、KaiwuDB 开发者中心或 JDBC 等连接器连接和使用 KWDB,具体连接和使用内容见 使用 kwbase CLI 工具连接 KWDB、 使用 KaiwuDB 开发者中心连接 KWDB 和 使用 JDBC 连接 KWDB。
第二章 KWDB基础概念
2.1 数据库与表
在KWDB中,数据库(Database)是最 高级别的数据容器,用于逻辑上组织相关数据。一个KWDB实例可以包含多个数据库,每个数据库包含多个表。
表(Table)是KWDB中存储数据的主要结构,由行(Row)和列(Column)组成。与传统数据库不同的是,KWDB的表具有动态模式特性,允许在不修改表结构的情况下添加新字段。
创建数据库的基本语法:
CREATE DATABASE database_name [WITH [OWNER = role_name] [ENCODING = encoding] [CONNECTION_LIMIT = max_connections];
示例:
CREATE DATABASE ecommerce WITH OWNER = admin ENCODING = 'UTF8' CONNECTION_LIMIT = 100;
切换当前数据库:
USE DATABASE ecommerce;
创建表的基本语法:
CREATE TABLE table_name ( column1 datatype [constraints], column2 datatype [constraints], ... ) [ENGINE = engine_type];
示例:
CREATE TABLE products ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100) NOT NULL, price DECIMAL(10,2) CHECK (price > 0), stock INT DEFAULT 0, description TEXT, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) ENGINE = 'InnoDB';
2.2 数据类型
KWDB支持丰富的数据类型,满足各种数据存储需求:
数值类型:
-
TINYINT:1字节整数(-128~127)
-
SMALLINT:2字节整数(-32,768~32,767)
-
INT/INTEGER:4字节整数
-
BIGINT:8字节整数
-
DECIMAL(p,s):精确小数,p为总位数,s为小数位
-
FLOAT:4字节单精度浮点数
-
DOUBLE:8字节双精度浮点数
字符串类型:
-
CHAR(n):固定长度字符串
-
VARCHAR(n):可变长度字符串(最大65535字节)
-
TEXT:长文本数据
-
JSON:JSON格式数据
日期时间类型:
-
DATE:日期(YYYY-MM-DD)
-
TIME:时间(HH:MM:SS)
-
DATETIME:日期时间(YYYY-MM-DD HH:MM:SS)
-
TIMESTAMP:时间戳(1970-01-01至今的秒数)
二进制类型:
-
BINARY(n):固定长度二进制
-
VARBINARY(n):可变长度二进制
-
BLOB:二进制大对象
特殊类型:
-
BOOLEAN:布尔值(TRUE/FALSE)
-
ENUM:枚举值
-
UUID:通用唯一标识符
2.3 约束与索引
约束(Constraints)用于保证数据的完整性和准确性:
-
PRIMARY KEY:主键约束,唯一标识每行记录
-
FOREIGN KEY:外键约束,维护表间关系
-
UNIQUE:唯一约束,确保列值不重复
-
NOT NULL:非空约束,禁止NULL值
-
CHECK:检查约束,验证数据满足条件
-
DEFAULT:默认值约束,为列提供默认值
示例:
CREATE TABLE orders (
order_id INT AUTO_INCREMENT PRIMARY KEY,
customer_id INT NOT NULL,
order_date DATETIME DEFAULT CURRENT_TIMESTAMP,
total_amount DECIMAL(12,2) CHECK (total_amount >= 0),
status ENUM('pending', 'processing', 'shipped', 'delivered') DEFAULT 'pending',
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
索引(Indexes)用于提高查询性能,常见索引类型:
-
普通索引:最基本的索引类型
-
唯一索引:确保索引列值唯一
-
复合索引:基于多个列的索引
-
全文索引:用于全文搜索
-
空间索引:用于地理空间数据
创建索引语法:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name ON table_name (column1 [ASC|DESC], ...);
示例:
-- 创建普通索引 CREATE INDEX idx_customer_name ON customers(last_name, first_name); -- 创建唯一索引 CREATE UNIQUE INDEX idx_product_code ON products(product_code); -- 创建全文索引 CREATE FULLTEXT INDEX idx_product_desc ON products(description);
2.4 视图与存储过程
视图(View)是基于SQL查询的虚拟表,简化复杂查询并增强安全性:
创建视图语法:
CREATE VIEW view_name AS SELECT column1, column2, ... FROM table_name WHERE condition;
示例:
CREATE VIEW active_customers AS SELECT customer_id, first_name, last_name, email FROM customers WHERE status = 'active' AND last_purchase_date > DATE_SUB(CURRENT_DATE, INTERVAL 6 MONTH);
存储过程(Stored Procedure)是预编译的SQL语句集合,提高代码重用性和安全性:
创建存储过程语法:
CREATE PROCEDURE procedure_name([parameters]) BEGIN -- SQL语句 END;
示例:
CREATE PROCEDURE update_product_price( IN p_product_id INT, IN p_price DECIMAL(10,2), OUT p_status VARCHAR(50) ) BEGIN IF p_price <= 0 THEN SET p_status = 'Error: Price must be positive'; ELSE UPDATE products SET price = p_price WHERE product_id = p_product_id; IF ROW_COUNT() > 0 THEN SET p_status = 'Success: Price updated'; ELSE SET p_status = 'Error: Product not found'; END IF; END IF; END;
调用存储过程:
CALL update_product_price(123, 29.99, @status); SELECT @status;
第三章 KWDB基本操作
3.1 数据操作语言(DML)
3.1.1 插入数据(INSERT)
基本插入语法:
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);
多行插入:
INSERT INTO products (name, price, category)
VALUES
('Laptop', 999.99, 'Electronics'),
('Desk Chair', 149.99, 'Furniture'),
('Coffee Mug', 9.99, 'Kitchen');
从查询结果插入:
INSERT INTO premium_products SELECT * FROM products WHERE price > 500;
3.1.2 查询数据(SELECT)
基本查询:
SELECT column1, column2, ... FROM table_name [WHERE condition] [ORDER BY column [ASC|DESC]] [LIMIT count];
示例:
-- 查询所有列 SELECT * FROM customers; -- 查询特定列 SELECT first_name, last_name, email FROM customers; -- 带条件的查询 SELECT name, price FROM products WHERE price > 100 AND stock > 0 ORDER BY price DESC LIMIT 10;
3.1.3 更新数据(UPDATE)
基本更新语法:
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;
示例:
-- 更新单个记录 UPDATE customers SET email = 'new.email@example.com', phone = '1234567890' WHERE customer_id = 1001; -- 基于当前值的更新 UPDATE products SET price = price * 1.1 -- 价格上涨10% WHERE category = 'Electronics'; -- 使用子查询更新 UPDATE orders SET status = 'completed' WHERE order_id IN ( SELECT order_id FROM payments WHERE payment_status = 'confirmed' );
3.1.4 删除数据(DELETE)
基本删除语法:
DELETE FROM table_name WHERE condition;
示例:
-- 删除特定记录 DELETE FROM customers WHERE last_activity_date < DATE_SUB(CURRENT_DATE, INTERVAL 5 YEAR); -- 清空表(谨慎使用,建议备份数据哦) DELETE FROM temp_logs;
3.2 数据查询进阶
3.2.1 条件表达式
KWDB支持丰富的条件表达式:
比较运算符:=, <>/!=, >, <, >=, <=
逻辑运算符:AND, OR, NOT
特殊运算符:
-
BETWEEN:范围匹配
-
IN:集合匹配
-
LIKE:模式匹配
-
IS NULL:空值检查
示例:
SELECT * FROM products
WHERE (price BETWEEN 50 AND 200)
AND (category IN ('Electronics', 'Appliances'))
AND (name LIKE '%Pro%')
AND (description IS NOT NULL);
3.2.2 聚合函数
常用聚合函数:
-
COUNT():计数
-
SUM():求和
-
AVG():平均值
-
MIN()/MAX():最小/最大值
-
GROUP_CONCAT():连接字符串
示例:
-- 基本聚合 SELECT COUNT(*) AS total_products, AVG(price) AS avg_price, MAX(price) AS max_price, MIN(price) AS min_price FROM products; -- 分组聚合 SELECT category, COUNT(*) AS product_count, AVG(price) AS avg_price FROM products GROUP BY category HAVING COUNT(*) > 5 -- HAVING用于过滤分组 ORDER BY avg_price DESC;
3.2.3 连接查询
内连接(INNER JOIN):只返回匹配的行
SELECT o.order_id, c.first_name, c.last_name, o.order_date FROM orders o INNER JOIN customers c ON o.customer_id = c.customer_id;
左外连接(LEFT JOIN):返回左表所有行,右表无匹配则为NULL
SELECT p.product_id, p.name, oi.quantity FROM products p LEFT JOIN order_items oi ON p.product_id = oi.product_id;
右外连接(RIGHT JOIN):返回右表所有行,左表无匹配则为NULL
SELECT d.department_name, e.employee_name FROM employees e RIGHT JOIN departments d ON e.department_id = d.department_id;
全外连接(FULL JOIN):返回两表所有行,无匹配则为NULL
SELECT c.category_name, p.product_name FROM categories c FULL JOIN products p ON c.category_id = p.category_id;
交叉连接(CROSS JOIN):笛卡尔积
SELECT s.size, c.color FROM sizes s CROSS JOIN colors c;
3.2.4 子查询
标量子查询:返回单个值
SELECT product_name, price, (SELECT AVG(price) FROM products) AS avg_price, price - (SELECT AVG(price) FROM products) AS diff_from_avg FROM products;
列子查询:返回单列多行
SELECT customer_id, first_name, last_name FROM customers WHERE customer_id IN ( SELECT DISTINCT customer_id FROM orders WHERE order_date > '2023-01-01' );
行子查询:返回单行多列
SELECT * FROM products WHERE (category, price) = ( SELECT category, MAX(price) FROM products WHERE category = 'Electronics' );
表子查询:返回多行多列
SELECT c.customer_name, o.order_count FROM customers c JOIN ( SELECT customer_id, COUNT(*) AS order_count FROM orders GROUP BY customer_id ) o ON c.customer_id = o.customer_id;
3.2.5 公用表表达式(CTE)
CTE(Common Table Expression)提高查询可读性:
基本语法:
WITH cte_name AS ( SELECT ... ) SELECT * FROM cte_name;
示例:
-- 简单CTE WITH high_value_orders AS ( SELECT order_id, customer_id, total_amount FROM orders WHERE total_amount > 1000 ) SELECT c.first_name, c.last_name, h.order_id, h.total_amount FROM high_value_orders h JOIN customers c ON h.customer_id = c.customer_id; -- 递归CTE(用于层次结构数据) WITH RECURSIVE org_hierarchy AS ( -- 基础查询(顶 级员工) SELECT employee_id, name, manager_id, 1 AS level FROM employees WHERE manager_id IS NULL UNION ALL -- 递归查询(下属员工) SELECT e.employee_id, e.name, e.manager_id, h.level + 1 FROM employees e JOIN org_hierarchy h ON e.manager_id = h.employee_id ) SELECT * FROM org_hierarchy ORDER BY level, name;
3.3 事务处理
事务(Transaction)是一组原子性的SQL操作,要么全部执行成功,要么全部失败回滚。
事务特性(ACID):
-
原子性(Atomicity):事务是不可分割的工作单位
-
一致性(Consistency):事务使数据库从一个一致状态变到另一个一致状态
-
隔离性(Isolation):事务执行不受其他事务干扰
-
持久性(Durability):事务一旦提交,其结果就是永 久性的
基本事务语法:
START TRANSACTION; -- SQL语句 COMMIT; -- 或 ROLLBACK;
示例:
START TRANSACTION; -- 扣除账户余额 UPDATE accounts SET balance = balance - 1000 WHERE account_id = 12345 AND balance >= 1000; -- 记录交易 INSERT INTO transactions (account_id, amount, transaction_type) VALUES (12345, 1000, 'withdrawal'); -- 检查是否成功 IF ROW_COUNT() > 0 THEN COMMIT; SELECT 'Transaction completed successfully' AS result; ELSE ROLLBACK; SELECT 'Transaction failed: insufficient funds' AS result; END IF;
事务隔离级别:
-
READ UNCOMMITTED:最低隔离级别,可能读取到未提交的数据(“脏读”)
-
READ COMMITTED:只能读取已提交的数据(默认级别)
-
REPEATABLE READ:确保同一事务中多次读取结果一致
-
SERIALIZABLE:最高隔离级别,完全串行化执行
设置隔离级别:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
第四章 KWDB高级特性
4.1 JSON支持
KWDB提供强大的JSON数据处理能力,可以存储和查询JSON文档。
JSON数据类型:
CREATE TABLE product_reviews ( review_id INT AUTO_INCREMENT PRIMARY KEY, product_id INT, review_data JSON, FOREIGN KEY (product_id) REFERENCES products(product_id) );
插入JSON数据:
INSERT INTO product_reviews (product_id, review_data)
VALUES (101, '{
"rating": 5,
"reviewer": "John Doe",
"comments": "Excellent product!",
"date": "2023-05-15",
"verified_purchase": true,
"helpful_votes": 12
}');
查询JSON数据:
-- 提取JSON字段 SELECT review_id, review_data->"$.rating" AS rating, review_data->"$.reviewer" AS reviewer FROM product_reviews WHERE review_data->"$.rating" >= 4; -- JSON路径查询 SELECT * FROM product_reviews WHERE JSON_EXTRACT(review_data, '$.verified_purchase') = true; -- 更新JSON数据 UPDATE product_reviews SET review_data = JSON_SET(review_data, '$.helpful_votes', 15) WHERE review_id = 1; -- 删除JSON属性 UPDATE product_reviews SET review_data = JSON_REMOVE(review_data, '$.date') WHERE review_id = 1;
4.2 全文搜索
KWDB提供全文索引功能,支持高效的文本搜索。
创建全文索引:
ALTER TABLE products ADD FULLTEXT INDEX ft_index_name_desc (name, description);
全文搜索查询:
-- 自然语言搜索
SELECT * FROM products
WHERE MATCH(name, description) AGAINST('wireless keyboard' IN NATURAL LANGUAGE MODE);
-- 布尔模式搜索
SELECT * FROM products
WHERE MATCH(name, description) AGAINST('+wireless -mouse' IN BOOLEAN MODE);
-- 查询扩展搜索
SELECT * FROM products
WHERE MATCH(name, description) AGAINST('laptop' WITH QUERY EXPANSION);
4.3 窗口函数
窗口函数(Window Functions)对一组行执行计算,同时保留原始行。
常用窗口函数:
-
ROW_NUMBER():行号
-
RANK()/DENSE_RANK():排名
-
LEAD()/LAG():访问前后行
-
FIRST_VALUE()/LAST_VALUE():窗口首尾值
-
NTILE():分组分位数
示例:
-- 为每个部门的员工按薪资排名 SELECT employee_id, first_name, last_name, department, salary, RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank, RANK() OVER (ORDER BY salary DESC) AS global_rank FROM employees; -- 计算移动平均 SELECT order_date, daily_revenue, AVG(daily_revenue) OVER ( ORDER BY order_date ROWS BETWEEN 2 PRECEDING AND CURRENT ROW ) AS moving_avg_3day FROM daily_sales; -- 计算同比环比 SELECT month, revenue, LAG(revenue, 1) OVER (ORDER BY month) AS prev_month, revenue - LAG(revenue, 1) OVER (ORDER BY month) AS mom_change, LAG(revenue, 12) OVER (ORDER BY month) AS prev_year_month, revenue - LAG(revenue, 12) OVER (ORDER BY month) AS yoy_change FROM monthly_sales;
4.4 分区表
分区表(Partitioned Tables)将大表物理分割为更小的部分,提高查询性能和管理效率。
常见分区策略:
-
范围分区(RANGE):基于列值范围
-
列表分区(LIST):基于列值列表
-
哈希分区(HASH):基于哈希函数
-
键分区(KEY):类似于哈希但使用KWDB内部机制
创建分区表示例:
-- 范围分区(按日期)
CREATE TABLE sales (
sale_id INT AUTO_INCREMENT,
sale_date DATE,
customer_id INT,
amount DECIMAL(12,2),
PRIMARY KEY (sale_id, sale_date)
)
PARTITION BY RANGE (YEAR(sale_date)) (
PARTITION p2020 VALUES LESS THAN (2021),
PARTITION p2021 VALUES LESS THAN (2022),
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION pmax VALUES LESS THAN MAXVALUE
);
-- 列表分区(按地区)
CREATE TABLE customers (
customer_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
region VARCHAR(20)
)
PARTITION BY LIST COLUMNS(region) (
PARTITION p_north VALUES IN ('Beijing', 'Tianjin', 'Hebei'),
PARTITION p_east VALUES IN ('Shanghai', 'Jiangsu', 'Zhejiang'),
PARTITION p_south VALUES IN ('Guangdong', 'Fujian', 'Hainan'),
PARTITION p_west VALUES IN ('Sichuan', 'Chongqing', 'Yunnan'),
PARTITION p_other VALUES IN (DEFAULT)
);
-- 哈希分区(均匀分布)
CREATE TABLE logs (
log_id BIGINT AUTO_INCREMENT PRIMARY KEY,
log_time DATETIME,
message TEXT,
severity ENUM('info', 'warning', 'error')
)
PARTITION BY HASH(log_id)
PARTITIONS 8;
管理分区:
-- 添加分区
ALTER TABLE sales ADD PARTITION (
PARTITION p2023 VALUES LESS THAN (2024)
);
-- 删除分区(数据也会删除)
ALTER TABLE sales DROP PARTITION p2020;
-- 重组分区
ALTER TABLE customers REORGANIZE PARTITION p_north, p_east INTO (
PARTITION p_north_east VALUES IN ('Beijing', 'Tianjin', 'Hebei', 'Shanghai', 'Jiangsu', 'Zhejiang')
);
-- 查询分区信息
SELECT * FROM information_schema.PARTITIONS
WHERE TABLE_NAME = 'sales';
第五章 KWDB性能优化
5.1 查询优化
5.1.1 EXPLAIN分析
使用EXPLAIN分析查询执行计划:
EXPLAIN SELECT c.customer_name, COUNT(o.order_id) AS order_count FROM customers c LEFT JOIN orders o ON c.customer_id = o.customer_id WHERE c.registration_date > '2022-01-01' GROUP BY c.customer_id HAVING COUNT(o.order_id) > 3 ORDER BY order_count DESC;
解读EXPLAIN结果关键列:
-
id:查询标识符
-
select_type:查询类型(SIMPLE, PRIMARY, SUBQUERY等)
-
table:访问的表
-
type:连接类型(从好到差:system > const > eq_ref > ref > range > index > ALL)
-
possible_keys:可能使用的索引
-
key:实际使用的索引
-
rows:预估检查的行数
-
Extra:额外信息(Using index, Using temporary, Using filesort等)
5.1.2 索引优化策略
1. 选择合适的列建立索引:
(1)高选择性的列(区分度高)
(2)常用于WHERE、JOIN、ORDER BY、GROUP BY的列
(3)避免过度索引,因为索引会降低写入性能
2.复合索引设计原则:
(1)最左前缀原则:索引(a,b,c)可用于查询条件a、a,b或a,b,c
(2)将选择性高的列放在前面
(3)考虑查询频率和排序方向
3.覆盖索引:索引包含查询所需的所有字段
-- 如果索引是(name, age),则以下查询可以使用覆盖索引 SELECT name, age FROM users WHERE name LIKE 'J%';
4.索引失效的常见情况:
(1)对索引列使用函数或运算:WHERE YEAR(create_time) = 2023
(2)使用不等于(!=或<>):WHERE status != 'active'
(3)使用NOT LIKE:WHERE name NOT LIKE 'A%'
(4)隐式类型转换:WHERE phone = 12345678(phone是字符串类型)
5.1.3 查询重写技巧
1.避免SELECT :只查询需要的列
2.使用LIMIT限制结果集:特别是与大表交互时
3.优化子查询:考虑重写为JOIN
-- 低效 SELECT * FROM products WHERE category_id IN (SELECT category_id FROM categories WHERE department = 'Electronics'); -- 高效 SELECT p.* FROM products p JOIN categories c ON p.category_id = c.category_id WHERE c.department = 'Electronics';
4.避免大事务:将大事务拆分为小事务
5.合理使用UNION ALL:UNION会去重,有性能开销
5.2 数据库配置优化
5.2.1 内存配置
关键内存参数:
-
innodb_buffer_pool_size:InnoDB缓冲池大小(通常设为物理内存的50-70%)
-
key_buffer_size:MyISAM键缓冲区大小
-
query_cache_size:查询缓存大小
-
sort_buffer_size:排序缓冲区大小
-
join_buffer_size:连接操作缓冲区大小
5.2.2 磁盘I/O优化
-
使用SSD存储:显著提高I/O性能
-
配置合适的RAID级别:RAID 10提供最佳性能
-
分离数据文件和日志文件:放在不同的物理设备上
-
调整InnoDB I/O参数:
(1)innodb_io_capacity:I/O容量设置
(2)innodb_flush_neighbors:SSD上可禁用
(3)innodb_read_io_threads/innodb_write_io_threads:I/O线程数
5.2.3 并发配置
-
max_connections:最大连接数
-
thread_cache_size:线程缓存大小
-
innodb_thread_concurrency:InnoDB并发线程数
-
table_open_cache:表缓存大小
5.3 数据库维护
5.3.1 定期维护任务
1.备份数据库:
# 使用KWDB工具备份 kwdb_dump -u username -p database_name > backup.sql # 使用mysqldump(兼容) mysqldump -u username -p database_name > backup.sql
2.优化表:
ANALYZE TABLE customers; -- 更新统计信息 OPTIMIZE TABLE orders; -- 重建表,整理碎片
3.监控性能:
-- 查看运行中的查询 SHOW PROCESSLIST;
-- 查看性能统计 SHOW STATUS LIKE 'Innodb%'; SHOW ENGINE INNODB STATUS;
5.3.2 慢查询日志
启用慢查询日志:
-- 设置慢查询阈值(秒) SET GLOBAL long_query_time = 1; -- 启用慢查询日志 SET GLOBAL slow_query_log = 'ON'; -- 指定日志文件 SET GLOBAL slow_query_log_file = '/var/log/kwdb-slow.log';
分析慢查询日志:
# 使用KWDB自带工具 kwdb_slow_log_analyzer /var/log/kwdb-slow.log # 使用mysqldumpslow(兼容) mysqldumpslow -s t /var/log/kwdb-slow.log
第六章 KWDB安全与权限
6.1 用户管理
创建用户:
CREATE USER 'username'@'host' IDENTIFIED BY 'password';
示例:
-- 允许从本地连接 CREATE USER 'app_user'@'localhost' IDENTIFIED BY 'SecurePass123!'; -- 允许从任何主机连接 CREATE USER 'reporting_user'@'%' IDENTIFIED BY 'ReportingPass456!';
修改用户:
-- 重命名用户 RENAME USER 'old_user'@'localhost' TO 'new_user'@'localhost'; -- 修改密码 ALTER USER 'username'@'host' IDENTIFIED BY 'new_password'; -- 密码过期策略 ALTER USER 'username'@'host' PASSWORD EXPIRE INTERVAL 90 DAY;
删除用户:
DROP USER 'username'@'host';
6.2 权限管理
授予权限:
GRANT privilege_type ON database_name.table_name TO 'username'@'host';
常用权限:
-
全局权限:CREATE USER, SHOW DATABASES, RELOAD, SHUTDOWN
-
数据库权限:CREATE, ALTER, DROP, GRANT OPTION
-
表权限:SELECT, INSERT, UPDATE, DELETE, INDEX
-
列权限:可指定特定列的权限
-
过程权限:EXECUTE, ALTER ROUTINE
示例:
-- 授予特定数据库的所有权限 GRANT ALL PRIVILEGES ON inventory.* TO 'app_user'@'localhost'; -- 授予特定表的SELECT和INSERT权限 GRANT SELECT, INSERT ON ecommerce.products TO 'reporting_user'@'%'; -- 授予特定列的UPDATE权限 GRANT UPDATE(name, price) ON ecommerce.products TO 'editor'@'localhost'; -- 授予创建和修改存储过程的权限 GRANT CREATE ROUTINE, ALTER ROUTINE ON *.* TO 'developer'@'localhost';
查看权限:
-- 查看自己的权限 SHOW GRANTS; -- 查看其他用户的权限 SHOW GRANTS FOR 'username'@'host';
撤销权限:
REVOKE privilege_type ON database_name.table_name FROM 'username'@'host';
6.3 数据安全最佳实践
1.最小权限原则:只授予用户必要的权限
2.使用角色管理权限:
-- 创建角色 CREATE ROLE 'read_only', 'app_developer'; -- 为角色授权 GRANT SELECT ON *.* TO 'read_only'; GRANT ALL ON app_db.* TO 'app_developer'; -- 将角色分配给用户 GRANT 'read_only' TO 'reporting_user'@'%'; GRANT 'app_developer' TO 'dev_user'@'localhost'; -- 激活角色 SET DEFAULT ROLE ALL TO 'reporting_user'@'%';
3.加密敏感数据:
-- 使用AES加密
INSERT INTO users (username, password)
VALUES ('admin', AES_ENCRYPT('secret', 'encryption_key'));
-- 查询时解密
SELECT username, AES_DECRYPT(password, 'encryption_key') AS password
FROM users;
4.审计日志:启用审计插件记录关键操作
5.网络安全性:
(1)使用SSL加密连接
(2)限制可访问的IP地址
(3)避免使用默认端口(3306)
第七章 KWDB应用
7.1 电商数据库设计示例
7.1.1 数据库架构
-- 用户表
CREATE TABLE users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) UNIQUE NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
password_hash VARCHAR(255) NOT NULL,
first_name VARCHAR(50),
last_name VARCHAR(50),
phone VARCHAR(20),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
status ENUM('active', 'inactive', 'suspended') DEFAULT 'active'
);
-- 用户地址表
CREATE TABLE user_addresses (
address_id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL,
address_type ENUM('home', 'work', 'other') DEFAULT 'home',
street_address VARCHAR(255) NOT NULL,
city VARCHAR(100) NOT NULL,
state VARCHAR(100),
postal_code VARCHAR(20),
country VARCHAR(100) DEFAULT 'United States',
is_default BOOLEAN DEFAULT FALSE,
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
-- 商品分类表
CREATE TABLE categories (
category_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
description TEXT,
parent_id INT,
is_active BOOLEAN DEFAULT TRUE,
FOREIGN KEY (parent_id) REFERENCES categories(category_id)
);
-- 商品表
CREATE TABLE products (
product_id INT AUTO_INCREMENT PRIMARY KEY,
category_id INT,
sku VARCHAR(50) UNIQUE NOT NULL,
name VARCHAR(255) NOT NULL,
description TEXT,
price DECIMAL(10,2) NOT NULL,
cost DECIMAL(10,2),
weight DECIMAL(8,2),
stock_quantity INT NOT NULL DEFAULT 0,
min_stock_level INT DEFAULT 5,
is_active BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (category_id) REFERENCES categories(category_id)
) ENGINE=InnoDB;
-- 商品图片表
CREATE TABLE product_images (
image_id INT AUTO_INCREMENT PRIMARY KEY,
product_id INT NOT NULL,
image_url VARCHAR(255) NOT NULL,
alt_text VARCHAR(255),
sort_order INT DEFAULT 0,
is_primary BOOLEAN DEFAULT FALSE,
FOREIGN KEY (product_id) REFERENCES products(product_id)
);
-- 订单表
CREATE TABLE orders (
order_id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT,
order_number VARCHAR(50) UNIQUE NOT NULL,
status ENUM('pending', 'processing', 'shipped', 'delivered', 'cancelled', 'returned') DEFAULT 'pending',
order_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
shipping_address_id INT,
billing_address_id INT,
subtotal DECIMAL(10,2) NOT NULL,
tax_amount DECIMAL(10,2) NOT NULL DEFAULT 0,
shipping_cost DECIMAL(10,2) NOT NULL DEFAULT 0,
total_amount DECIMAL(10,2) NOT NULL,
payment_method ENUM('credit_card', 'paypal', 'bank_transfer', 'cod'),
payment_status ENUM('pending', 'paid', 'failed', 'refunded') DEFAULT 'pending',
notes TEXT,
FOREIGN KEY (user_id) REFERENCES users(user_id),
FOREIGN KEY (shipping_address_id) REFERENCES user_addresses(address_id),
FOREIGN KEY (billing_address_id) REFERENCES user_addresses(address_id)
);
-- 订单商品表
CREATE TABLE order_items (
item_id INT AUTO_INCREMENT PRIMARY KEY,
order_id INT NOT NULL,
product_id INT NOT NULL,
quantity INT NOT NULL DEFAULT 1,
unit_price DECIMAL(10,2) NOT NULL,
discount_amount DECIMAL(10,2) DEFAULT 0,
total_price DECIMAL(10,2) NOT NULL,
FOREIGN KEY (order_id) REFERENCES orders(order_id),
FOREIGN KEY (product_id) REFERENCES products(product_id)
);
-- 库存变动表
CREATE TABLE inventory_transactions (
transaction_id INT AUTO_INCREMENT PRIMARY KEY,
product_id INT NOT NULL,
quantity_change INT NOT NULL,
transaction_type ENUM('purchase', 'sale', 'return', 'adjustment', 'damage') NOT NULL,
reference_id INT COMMENT 'Order ID or other reference',
notes TEXT,
created_by INT COMMENT 'User ID who made the change',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (product_id) REFERENCES products(product_id)
);
7.1.2 常用业务查询
1.用户购物车内容:
SELECT p.product_id, p.name, p.price, ci.quantity, (p.price * ci.quantity) AS item_total FROM cart_items ci JOIN products p ON ci.product_id = p.product_id WHERE ci.user_id = 123 ORDER BY ci.added_at DESC;
2.生成订单报表:
SELECT DATE_FORMAT(o.order_date, '%Y-%m') AS month, COUNT(DISTINCT o.order_id) AS order_count, COUNT(oi.item_id) AS item_count, SUM(o.total_amount) AS total_sales, AVG(o.total_amount) AS avg_order_value FROM orders o JOIN order_items oi ON o.order_id = oi.order_id WHERE o.order_date BETWEEN '2023-01-01' AND '2023-12-31' GROUP BY DATE_FORMAT(o.order_date, '%Y-%m') ORDER BY month;
3.库存预警查询:
SELECT p.product_id, p.sku, p.name, p.stock_quantity, p.min_stock_level, c.name AS category FROM products p JOIN categories c ON p.category_id = c.category_id WHERE p.stock_quantity <= p.min_stock_level AND p.is_active = TRUE ORDER BY p.stock_quantity ASC;
4.热门商品分析:
SELECT p.product_id, p.name, COUNT(oi.item_id) AS times_ordered, SUM(oi.quantity) AS total_quantity, SUM(oi.total_price) AS total_revenue FROM order_items oi JOIN products p ON oi.product_id = p.product_id JOIN orders o ON oi.order_id = o.order_id WHERE o.order_date >= DATE_SUB(CURRENT_DATE, INTERVAL 3 MONTH) GROUP BY p.product_id, p.name ORDER BY total_revenue DESC LIMIT 10;
7.2 数据分析应用
7.2.1 销售漏斗分析
WITH funnel_stages AS ( SELECT COUNT(DISTINCT session_id) AS visitors, COUNT(DISTINCT CASE WHEN added_to_cart = TRUE THEN session_id END) AS cart_adders, COUNT(DISTINCT CASE WHEN reached_checkout = TRUE THEN session_id END) AS checkout_reachers, COUNT(DISTINCT CASE WHEN purchase_completed = TRUE THEN session_id END) AS purchasers FROM user_sessions WHERE session_date = CURRENT_DATE ) SELECT visitors, cart_adders, ROUND(cart_adders * 100.0 / visitors, 2) AS cart_rate, checkout_reachers, ROUND(checkout_reachers * 100.0 / cart_adders, 2) AS checkout_rate, purchasers, ROUND(purchasers * 100.0 / checkout_reachers, 2) AS conversion_rate, ROUND(purchasers * 100.0 / visitors, 2) AS overall_conversion FROM funnel_stages;
7.2.2 客户生命周期价值(CLV)
WITH customer_stats AS (
SELECT
user_id,
MIN(order_date) AS first_purchase,
MAX(order_date) AS last_purchase,
COUNT(DISTINCT order_id) AS order_count,
SUM(total_amount) AS total_revenue
FROM orders
WHERE order_date >= DATE_SUB(CURRENT_DATE, INTERVAL 1 YEAR)
AND status NOT IN ('cancelled')
GROUP BY user_id
)
SELECT
FLOOR(DATEDIFF(last_purchase, first_purchase) / 30) AS customer_tenure_months,
COUNT(user_id) AS customer_count,
AVG(order_count) AS avg_orders,
AVG(total_revenue) AS avg_revenue,
AVG(total_revenue / order_count) AS avg_order_value
FROM customer_stats
GROUP BY FLOOR(DATEDIFF(last_purchase, first_purchase) / 30)
ORDER BY customer_tenure_months;
7.2.3 A/B测试分析
SELECT test_group, COUNT(DISTINCT user_id) AS users, COUNT(DISTINCT CASE WHEN purchased = 1 THEN user_id END) AS purchasers, ROUND(COUNT(DISTINCT CASE WHEN purchased = 1 THEN user_id END) * 100.0 / COUNT(DISTINCT user_id), 2) AS conversion_rate, ROUND(AVG(order_value), 2) AS avg_order_value, ROUND(SUM(order_value) / COUNT(DISTINCT user_id), 2) AS revenue_per_user FROM ( SELECT u.user_id, u.test_group, CASE WHEN o.order_id IS NOT NULL THEN 1 ELSE 0 END AS purchased, COALESCE(o.total_amount, 0) AS order_value FROM users u LEFT JOIN orders o ON u.user_id = o.user_id WHERE u.signup_date BETWEEN '2023-06-01' AND '2023-06-30' AND o.order_date <= DATE_ADD(u.signup_date, INTERVAL 7 DAY) ) AS user_results GROUP BY test_group;
7.3 与应用程序集成
7.3.1 Python连接KWDB
import kwdb_connector # KWDB官方Python驱动 import pandas as pd # 创建连接 conn = kwdb_connector.connect( host='localhost', user='app_user', password='SecurePass123!', database='ecommerce' ) # 执行查询 def get_products_by_category(category_id): query = """ SELECT product_id, name, price, stock_quantity FROM products WHERE category_id = %s AND is_active = TRUE ORDER BY price """ return pd.read_sql(query, conn, params=(category_id,)) # 执行更新 def update_product_price(product_id, new_price): cursor = conn.cursor() try: cursor.execute( "UPDATE products SET price = %s WHERE product_id = %s", (new_price, product_id) ) conn.commit() return cursor.rowcount except Exception as e: conn.rollback() raise e finally: cursor.close() # 使用连接池 from kwdb_connector.pooling import ConnectionPool pool = ConnectionPool( host='localhost', user='app_user', password='SecurePass123!', database='ecommerce', pool_size=5 ) def get_user_orders(user_id): with pool.get_connection() as conn: query = """ SELECT o.order_id, o.order_date, o.total_amount, o.status, COUNT(oi.item_id) AS item_count FROM orders o LEFT JOIN order_items oi ON o.order_id = oi.order_id WHERE o.user_id = %s GROUP BY o.order_id ORDER BY o.order_date DESC """ return pd.read_sql(query, conn, params=(user_id,))
7.3.2 Java连接KWDB
import com.kwdb.jdbc.Driver;
import java.sql.*;
public class KWDBExample {
private static final String URL = "jdbc:kwdb://localhost:3306/ecommerce";
private static final String USER = "app_user";
private static final String PASSWORD = "SecurePass123!";
public List getFeaturedProducts() throws SQLException {
List products = new ArrayList<>();
try (Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(
"SELECT product_id, name, price FROM products " +
"WHERE is_featured = TRUE AND is_active = TRUE " +
"ORDER BY created_at DESC LIMIT 10")) {
while (rs.next()) {
Product product = new Product();
product.setId(rs.getInt("product_id"));
product.setName(rs.getString("name"));
product.setPrice(rs.getBigDecimal("price"));
products.add(product);
}
}
return products;
}
public int updateInventory(int productId, int quantityChange, String transactionType, String notes) {
String sql = "INSERT INTO inventory_transactions " +
"(product_id, quantity_change, transaction_type, notes, created_at) " +
"VALUES (?, ?, ?, ?, NOW())";
try (Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, productId);
pstmt.setInt(2, quantityChange);
pstmt.setString(3, transactionType);
pstmt.setString(4, notes);
return pstmt.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
return 0;
}
}
}
7.3.3 Node.js连接KWDB
const kwdb = require('kwdb-driver');
// 创建连接池
const pool = kwdb.createPool({
host: 'localhost',
user: 'app_user',
password: 'SecurePass123!',
database: 'ecommerce',
connectionLimit: 10
});
// 查询示例
async function getCustomerOrders(customerId) {
const query = `
SELECT o.order_id, o.order_date, o.total_amount, o.status,
COUNT(oi.item_id) AS item_count
FROM orders o
LEFT JOIN order_items oi ON o.order_id = oi.order_id
WHERE o.user_id = ?
GROUP BY o.order_id
ORDER BY o.order_date DESC
`;
try {
const [rows] = await pool.execute(query, [customerId]);
return rows;
} catch (err) {
console.error('Error fetching customer orders:', err);
throw err;
}
}
// 事务示例
async function placeOrder(orderData) {
const conn = await pool.getConnection();
try {
await conn.beginTransaction();
// 插入订单
const [orderResult] = await conn.execute(
`INSERT INTO orders
(user_id, order_number, status, total_amount, payment_method)
VALUES (?, ?, 'pending', ?, ?)`,
[orderData.userId, generateOrderNumber(), orderData.totalAmount, orderData.paymentMethod]
);
const orderId = orderResult.insertId;
// 插入订单商品
for (const item of orderData.items) {
await conn.execute(
`INSERT INTO order_items
(order_id, product_id, quantity, unit_price, total_price)
VALUES (?, ?, ?, ?, ?)`,
[orderId, item.productId, item.quantity, item.price, item.price * item.quantity]
);
// 更新库存
await conn.execute(
`UPDATE products SET stock_quantity = stock_quantity - ?
WHERE product_id = ? AND stock_quantity >= ?`,
[item.quantity, item.productId, item.quantity]
);
}
await conn.commit();
return orderId;
} catch (err) {
await conn.rollback();
throw err;
} finally {
conn.release();
}
}
第八章 KWDB实践
8.1 数据库设计规范
1.命名约定:
(1)表名:复数名词,小写加下划线,如products, order_items
(2)列名:小写加下划线,如created_at, product_name
(3)主键:表名单数形式加_id,如product_id, user_id
(4)外键:与被引用表的主键同名
2.主键选择:
(1)优先使用自增整数作为代理主键
(2)业务主键需确保唯一性和不变性
(3)避免使用复合主键,除非有特殊需求
3.字段设计:
(1)为所有表添加created_at和updated_at时间戳
(2)避免使用ENUM,改用查找表,除非值固定不变
(3)大文本字段(TEXT/BLOB)单独存储,避免影响主表性能
4.关系设计:
(1)一对多关系:在多方表添加外键
(2)多对多关系:使用关联表
(3)一对一关系:考虑表合并,除非有充分理由分开
8.2 SQL编写规范
1.格式化:
(1)关键字大写:SELECT, FROM, WHERE
(2)子句换行对齐
(3)缩进嵌套逻辑
2.性能考虑:
(1)避免SELECT *,只查询需要的列
(2)使用参数化查询防止SQL注入
(3)大表查询必须带条件
3.可读性:
(1)使用表别名保持简洁
(2)复杂查询添加注释
(3)公用表达式(CTE)替代嵌套子查询
4.示例对比:
不良实践:
select * from users u join orders o on u.id=o.user_id where u.status='active' and o.create_time>'2023-01-01';
良好实践:
SELECT u.user_id, u.username, u.email, o.order_id, o.order_date, o.total_amount FROM users u JOIN orders o ON u.user_id = o.user_id WHERE u.status = 'active' AND o.order_date > '2023-01-01' ORDER BY o.order_date DESC;
8.3 性能监控与调优
1.监控指标:
(1)查询响应时间
(2)并发连接数
(3)缓存命中率
(4)锁等待时间
2.定期维护:
-- 更新统计信息 ANALYZE TABLE customers, orders, products; -- 优化表结构 OPTIMIZE TABLE large_log_table; -- 检查表完整性 CHECK TABLE important_data REPAIR;
3.性能调优流程:
(1)识别慢查询(慢查询日志)
(2)分析执行计划(EXPLAIN)
(3)优化查询或索引
(4)测试性能改进
(5)监控生产环境
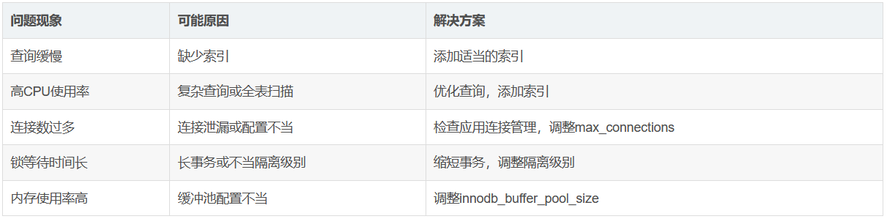
4.常见性能问题解决方案:
8.4 备份与恢复策略
1.备份类型:
(1) 完整备份:整个数据库的完整副本
(2) 增量备份:仅备份自上次备份后的变更
(3) 差异备份:备份自上次完整备份后的所有变更
2.备份方法:
# 逻辑备份(适合小型数据库) kwdb_dump -u root -p --databases ecommerce > ecommerce_backup.sql # 物理备份(适合大型数据库) kwdbbackup --user=root --password --backup-dir=/backups
3.备份自动化:
# 每日完整备份脚本示例
#!/bin/bash
BACKUP_DIR="/var/backups/kwdb"
DATE=$(date +%Y%m%d)
mkdir -p $BACKUP_DIR/$DATE
kwdb_dump -u backup_user -p'password' --all-databases \
--routines --events --triggers \
> $BACKUP_DIR/$DATE/full_backup.sql
# 保留最近7天备份
find $BACKUP_DIR -type d -mtime +7 -exec rm -rf {} \;
4.恢复流程:
# 停止应用服务 systemctl stop application.service # 恢复数据库 kwdb -u root -p < full_backup.sql # 应用增量备份(如果有) kwdbbinlog --start-datetime="2023-10-01 00:00:00" \ --stop-datetime="2023-10-02 00:00:00" \ /var/lib/kwdb/mysql-bin.000123 | kwdb -u root -p # 验证数据完整性 kwdbcheck --all-databases # 重启应用服务 systemctl start application.service
5.灾难恢复计划:
(1)文档化恢复步骤和责任人
(2)定期测试恢复流程
(3)确保异地备份
(4)定义RTO(恢复时间目标)和RPO(恢复点目标)
第九章 常见问题解答
9.1 初学者常见问题
Q1:如何选择合适的数据类型?
A:选择数据类型时应考虑:
-
数据特性:数字、文本、日期等
-
数据范围:如INT(最大约21亿) vs BIGINT
-
存储空间:如VARCHAR(255) vs TEXT
-
计算需求:需要数学计算的用数值类型
-
特殊功能:如JSON类型提供文档处理能力
Q2:为什么我的简单查询也很慢?
A:可能原因:
-
缺少必要的索引
-
表数据量过大且无适当分区
-
服务器资源不足(内存、CPU)
-
锁等待或阻塞事务
-
网络延迟(远程数据库)
Q3:CHAR和VARCHAR有什么区别?
A:
-
CHAR是固定长度,适合存储长度基本相同的字符串(如MD5哈希)
-
VARCHAR是可变长度,适合长度变化大的字符串(如用户名)
-
CHAR会填充空格到指定长度,VARCHAR只存储实际内容
Q4:如何处理大文本字段?
A:
-
如果很少查询,可单独存储在另一表
-
考虑使用FULLTEXT索引支持搜索
-
对于日志类数据,考虑归档策略
-
评估是否真的需要存储在数据库中
9.2 开发常见问题
Q1:如何优化大量数据的插入?
A:
1.使用批量插入代替单条插入
INSERT INTO table VALUES (1), (2), (3); -- 优于多次单条插入
2.临时禁用索引和约束
ALTER TABLE large_table DISABLE KEYS; -- 批量插入数据 ALTER TABLE large_table ENABLE KEYS;
3.使用LOAD DATA INFILE从文件导入
4.增加事务批次大小,但避免单个超大事务
Q2:如何安全地修改生产环境的表结构?
A:
-
先在测试环境验证变更
-
使用在线DDL工具(如pt-online-schema-change)
-
在低峰期执行变更
-
做好备份和回滚计划
-
考虑使用蓝绿部署策略
Q3:如何处理并发更新冲突?
A:
1.乐观锁:使用版本号字段
UPDATE products SET stock = stock - 1, version = version + 1 WHERE product_id = 123 AND version = 5;
2.悲观锁:在事务开始时锁定行
BEGIN; SELECT * FROM orders WHERE order_id = 100 FOR UPDATE; -- 执行更新 COMMIT;
3.应用层队列处理高并发写操作
Q4:如何设计高效的分页查询?
A:
避免使用LIMIT offset, size处理大偏移量:
-- 低效(偏移量越大越慢) SELECT * FROM large_table LIMIT 1000000, 20; -- 高效(使用索引列定位) SELECT * FROM large_table WHERE id > 1000000 -- 上次查询的最后ID ORDER BY id LIMIT 20;
9.3 运维常见问题
Q1:如何监控KWDB性能?
A:
1.使用内置性能视图:
SHOW STATUS LIKE 'Innodb%'; SHOW ENGINE INNODB STATUS;
2.启用慢查询日志
3.使用监控工具如Prometheus+Grafana
4.定期检查关键指标:
(1)查询响应时间
(2)连接数
(3)缓冲池命中率
(4)锁等待
Q2:如何解决连接数过多问题?
A:
1.检查应用是否有连接泄漏
2.优化连接池配置:
(1)适当的最大连接数
(2)合理的空闲连接超时
3.增加max_connections参数(需相应调整内存)
4.使用连接池中间件(如ProxySQL)
Q3:如何安全地升级KWDB版本?
A:
-
完整备份所有数据库
-
在测试环境验证升级过程
-
检查版本变更说明中的不兼容变更
-
制定回滚计划
-
在维护窗口期执行升级
-
升级后运行完整性检查
Q4:如何优化KWDB内存配置?
A:
关键内存参数:
-
innodb_buffer_pool_size:通常设为物理内存的50-70%
-
key_buffer_size:MyISAM表使用(如不使用可设小值)
-
query_cache_size:KWDB 8.0+已移除
-
sort_buffer_size/join_buffer_size:每个连接独占,不宜过大
调整步骤:
-
监控当前内存使用
-
根据工作负载特点调整参数
-
逐步测试调整效果
-
避免交换内存使用(swappiness=0)
第十章 KWDB学习资源与未来发展
10.1 官方学习资源
1.KWDB社区版GitHub仓库:
(1)源码访问
(2)问题追踪
(3)贡献指南
(4)地址:KWDB
2.KWDB官方博客:
(1)最佳实践分享
(2)新特性介绍
(3)性能优化技巧
(4)地址:社区版博客
10.2 KWDB未来发展趋势
1.云原生集成:
(1)更好的Kubernetes支持
(2)自动化扩展能力
(3)多云部署方案
2.AI增强:
(1)智能查询优化
(2)自动索引建议
(3)异常检测与自愈
3.边缘计算支持:
(1)轻量级边缘版本
(2)离线同步能力
(3)低延迟数据处理
4.增强的分析能力:
(1)内置机器学习算法
(2)实时流处理
(3)高级时间序列支持
5.开发者体验改进:
(1)更直观的管理工具
(2)增强的SDK支持
(3)简化的大数据处理接口
10.3 社区参与建议
1.参与方式:
(1)报告问题和建议
(2)贡献文档翻译
(3)提交代码补丁
(4)分享使用案例
2.本地用户组:
(1)参加或组织线下Meetup
(2)参与年度KWDB大会
(3)加入专业技术论坛
3.开源贡献:
(1)从解决小问题开始
(2)遵循贡献者指南
(3)参与代码审查讨论
结语
通过本指南的系统学习,你已经掌握了KWDB从基础概念到高级特性的全面知识。
希望本文能成为你KWDB学习之旅的有力助手,祝你在数据管理的道路上不断进步,创造更多价值!
本文写作仓促,不足之处请大家多多指正!谢谢!(其他后面会慢慢发布)