在上一篇《 Claude Code × 智谱 BigModel 实战集成指南》中,我们已经完成了一次完整的项目实战。项目 可以正常运行,但在后续代码 Review 时,一个问题逐渐暴露出来:
生成的代码虽然能跑,但大量 API 和用法已经过时,与最新官方文档存在明显偏差。
这在 AI 辅助开发中其实非常常见——模型的训练数据更新速度,往往赶不上框架和 SDK 的迭代速度。
正巧这时,一位朋友向我推荐了 Anthropic 最新发布的 Agent Skills,通过 plugins 的方式,让 Claude 在生成代码时 动态读取最新官方文档和工具能力,从而显著降低“写得像,但跑不通”的概率。
本文就是这次探索的完整记录。
一、Agent Skills 是什么?
官方仓库地址:
Agent Skills 可以理解为:
一套可插拔的“能力模块”,用于教会 Claude 如何用正确的方法、最新的工具、可重复的流程 来完成特定任务。
在技术层面上:
- 每个 Skill 本质上是一个文件夹
- 内部包含:
- 指令(instructions)
- 脚本(scripts)
- 资源文件(resources)
- Claude Code 会在运行时动态加载这些 Skills
它能解决什么问题?
Agent Skills 的核心价值在于 “降低幻觉 + 提高一致性”,典型应用场景包括:
- 按公司/团队的编码规范生成代码
- 按最新官方文档调用 API(而不是靠模型记忆)
- 执行固定的工程化流程(初始化项目、生成目录结构、部署脚本等)
- 自动化个人或组织级任务
简单来说:
Skills 不是让模型更聪明,而是让模型更“守规矩”。
二、在 Claude Code 中安装 Agent Skills
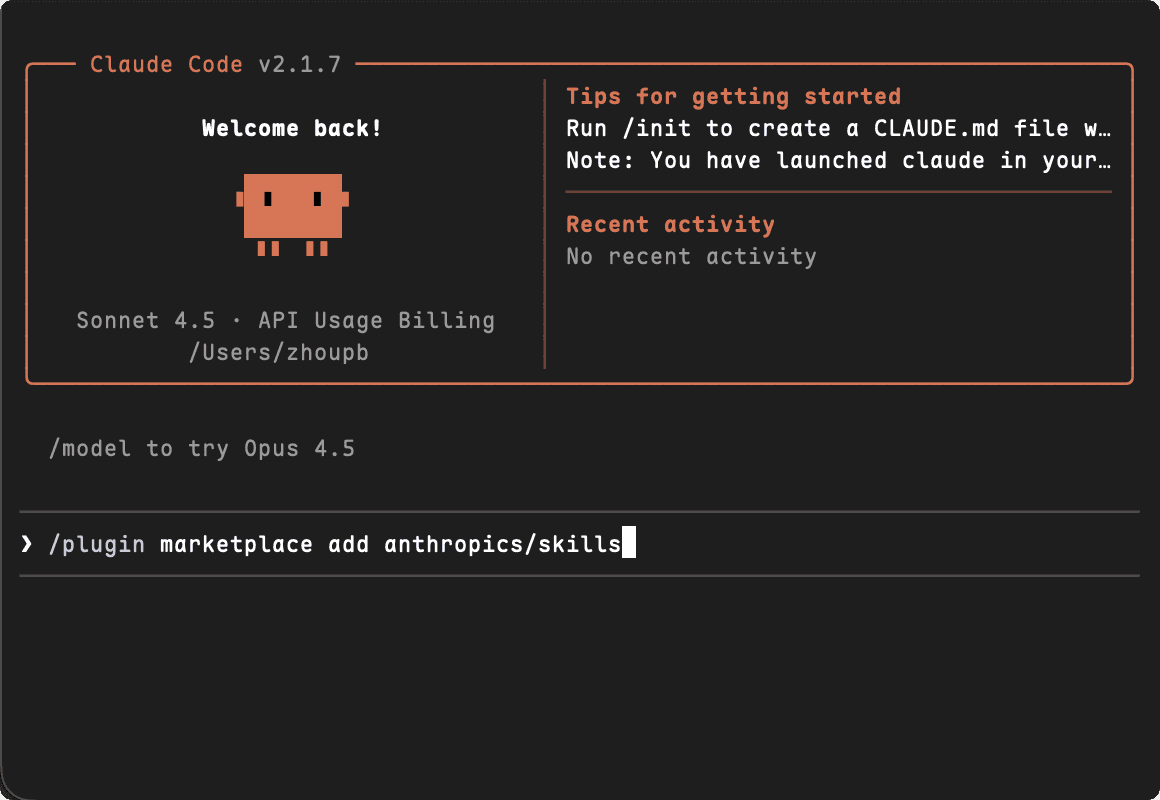
在 Claude Code 命令行中执行:
/plugin marketplace add anthropics/skills
安装完成后,你就已经具备了使用官方 Skills 的能力。
这一步相当于为 Claude Code 打开了“官方增强模式”。
三、创建自定义 Skill
1️⃣ 文件夹结构
在
~/.claude/skills/my-custom-skill
my-custom-skill/ ├── SKILL.md # Skill 描述 ├── helpers.py # 可选脚本 └── resources/ # 可选资源文件,比如模板、样例数据
2️⃣ SKILL.md 内容规范
--- name: my-custom-skill # Skill 名称 version: 1.0 # 版本号 description: | 这是一个自定义 Skill 示例。 它可以让 Claude 使用Context7 访问最新API生成。 tags: - report - markdown --- # 详细说明 - 输入格式要求:纯文本或JSON - 输出格式要求:Markdown - 步骤: 1. 分析输入内容 2. 输出最终文档 3. 生成符合最新 API 代码 # 示例 输入: - 使用 langgraph 最新文档 输出: -
3️⃣ 验证是否生效
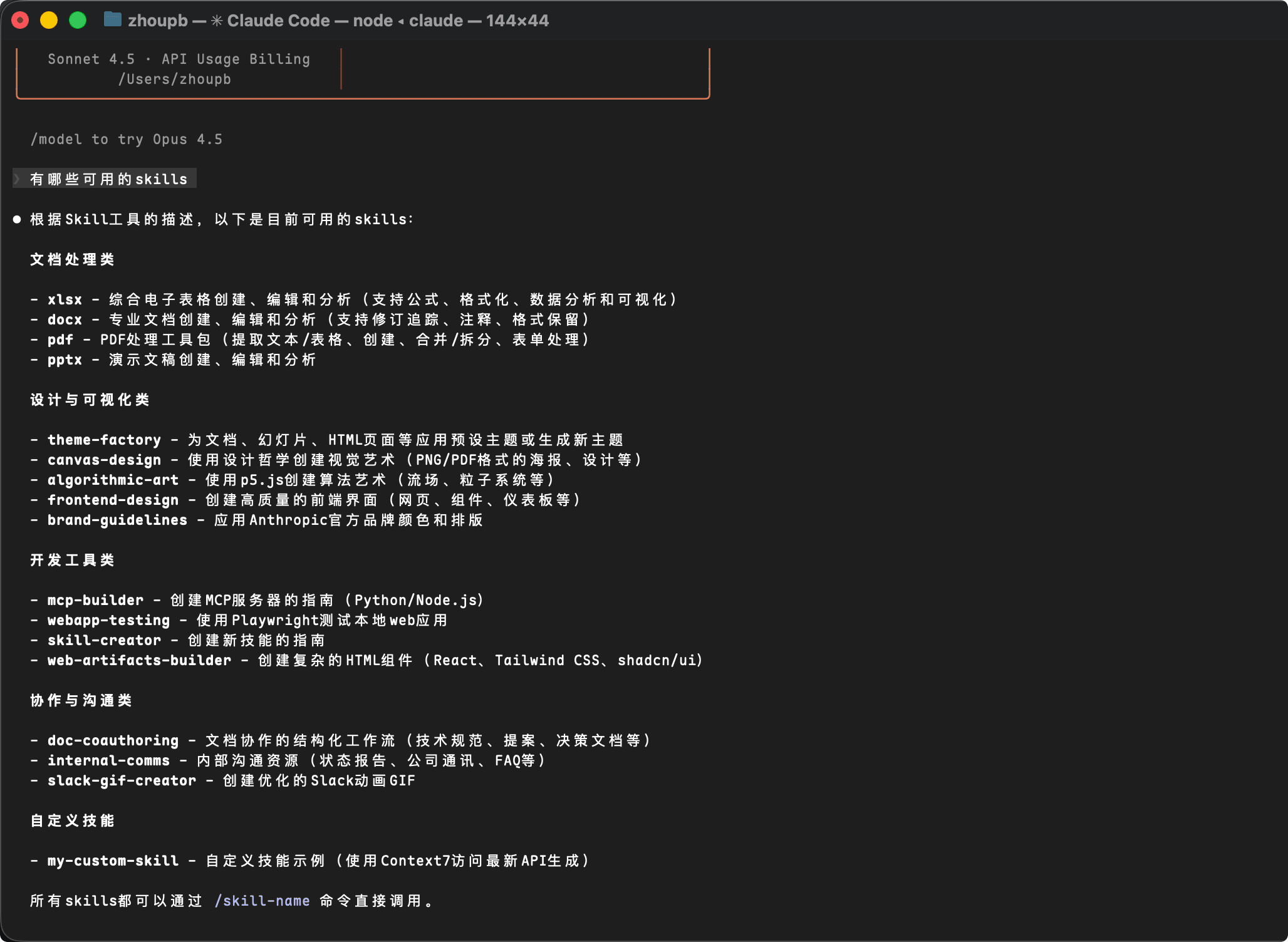
在 Claude 中输入
有哪些可用的Skill
4️⃣ 使用自定义 Skill
使用 Skill: my-custom-skill 帮我生成一个 Markdown 报告,内容如下: - xxx - xxx xxx
四、安装 context7 插件
接下来是本文的重点: context7。
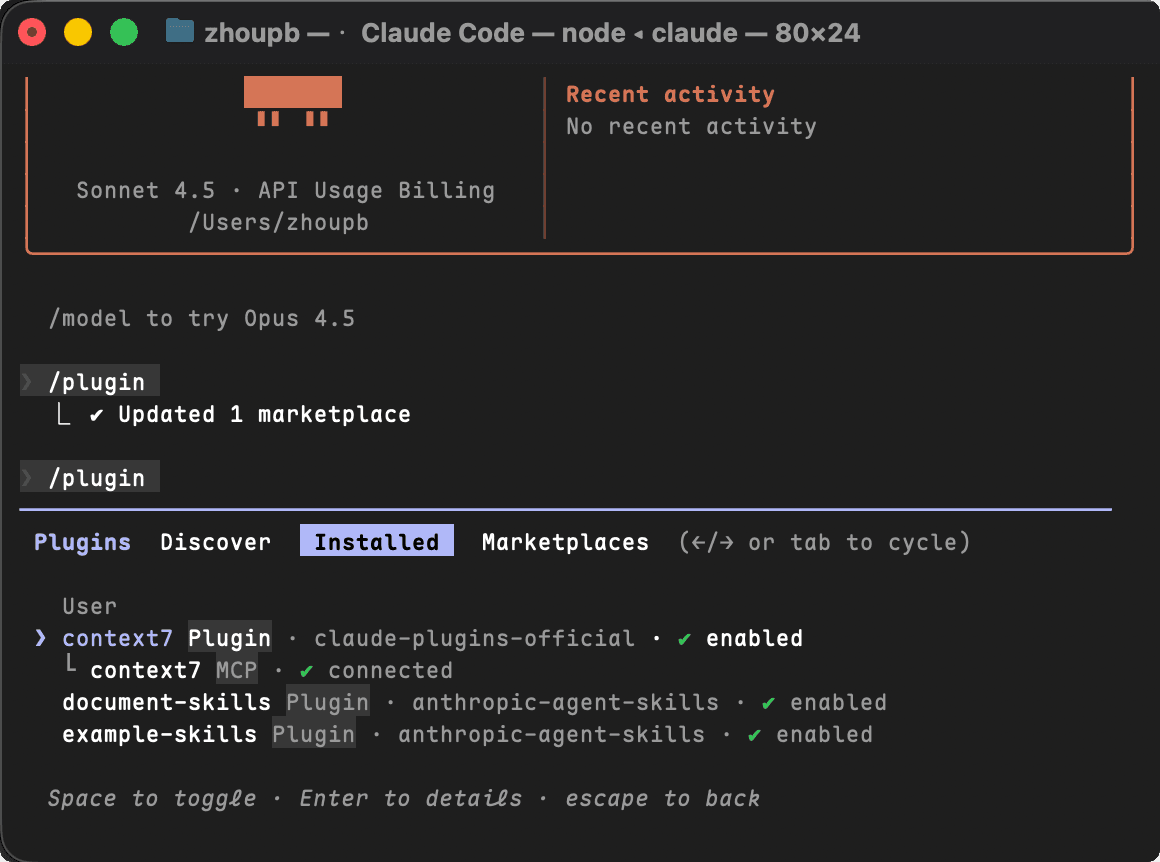
1️⃣ 打开插件管理
在 Claude Code 中输入:
/plugins
然后使用键盘 ➡️ 进入 Discover。
2️⃣ 搜索并安装 context7
在搜索框中输入
context7,完成安装。
context7 本质上是一个 MCP(Model Context Protocol)插件, 能让 Claude 直接参考并对齐最新的官方文档内容。
五、结合 context7 生成项目代码
安装完成后,就可以在 Prompt 中显式声明使用
context7。
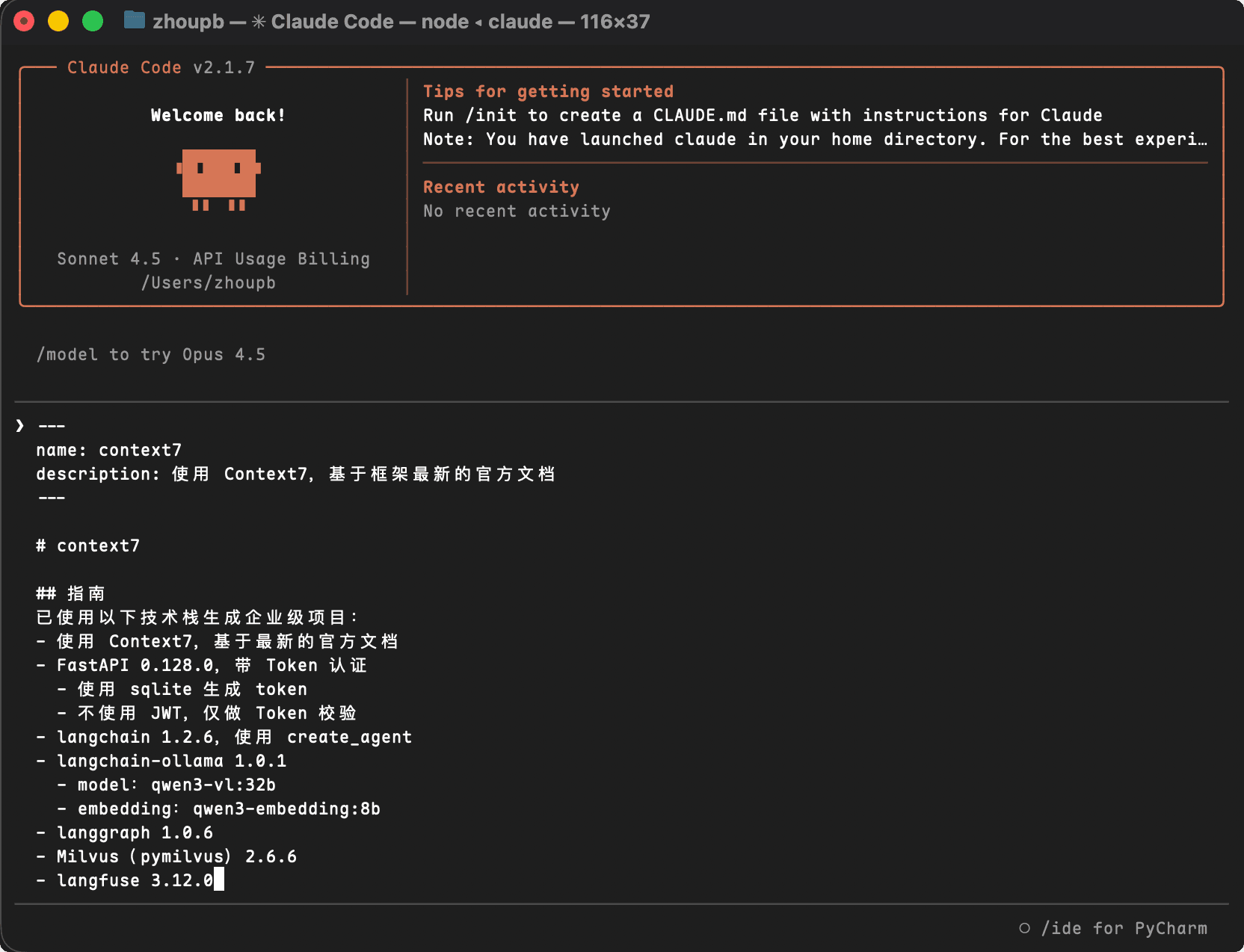
示例 Prompt
使用 Skill: my-custom-skill # 指南 已使用以下技术栈生成企业级项目: - FastAPI 0.128.0,带 Token 认证 - 使用 sqlite 生成 token - 不使用 JWT,仅做 Token 校验 - langchain 1.2.6,使用 create_agent - langchain-ollama 1.0.1 - model:qwen3-vl:32b - embedding:qwen3-embedding:8b - langgraph 1.0.6 - Milvus(pymilvus)2.6.6 - langfuse 3.12.0 # 约束 - 使用 Context7,基于最新的官方文档
通过这种方式,你是在 明确告诉 Claude:
不要靠“印象”写代码,而是 以当前官方文档为准。
六、实际体验与问题分析
真实结论只有一句话:
效果明显提升,但依然不能“一次生成直接可用”。
优点
- API 使用明显更接近最新文档
- 过时参数、废弃方法显著减少
- 工程结构更合理,思路更偏向“真实项目”
仍然存在的问题
- 复杂技术栈组合(LangChain + LangGraph + Milvus + Langfuse)
- 仍然需要 多轮调试才能完全跑通
- 某些边界用法依然存在偏差
我的判断
并不是 context7 不行,而是模型生成速度,依然落后于框架演进速度。
context7 做到的是:
- 让 Claude 看得到 最新文档
- 但最终“怎么拼起来”,仍然依赖模型本身的推理与代码能力
七、总结
如果你正在使用 Claude Code 做偏工程化、偏企业级的项目开发,我的建议是:
✅ 一定要上 Agent Skills
✅ 能用 context7 就用 context7
❌ 不要再完全相信“模型记忆里的 API”
但同时也要有一个清醒认知:
AI 辅助开发 = 更快的起点,而不是免调试的终点。
在当前阶段,最理想的模式依然是:
AI 生成 + 人类 Review + 多轮修正
后续我也会继续记录 Claude Code + MCP + 多模型协作 的实践经验,欢迎关注。