存储产品自从 SSD 出现后,数据访问性能大幅提升也促进上层应用架构方案的革新。高性能、低成本,耐久性好通常是这类 SSD 选型专注点。近几年业务数据爆发式增长,数据处理的性能要求和挑战越来越大。随着摩尔定律的失效,CPU 处理器性能提升速度减缓。CPU 计算也从通用计算向专用计算发展,为降低 CPU 负载,网卡和存储设备里都引入计算引擎承担部分运算,可计算存储(
CSD,computational storage drives)应运而生。
在存储中加入透明压缩是可计算存储商业化的最佳选择,主要有两个原因:
-
(1) 零采用障碍:存储内透明压缩不需要对现有存储
I /O 软件堆栈进行任何更改(例如文件系统、BLOCK 层和驱动程序)和
I/O 接口协议(例如
NVMe 和
SATA)。这确保了在其无缝集成和部署到现有基础设施中,无需用户应用程序去更改任一代码。
-
(2) 显著收益:除了非常广泛的适用性之外,传统无损数据压缩技术(
LZ77 及其变体,如
lz4、
zlib 和
ZSTD)涉及大量随机数据访问,这不可避免地会导致非常高的
CPU/ GPU 缓存未命中率,从而使
CPU/GPU 硬件利用率偏低。因此,减轻主机
CPU/GPU 执行无损数据压缩的负担变得非常有必要。
经过 3 年多的紧张研发,ScaleFlux 在2021年发布了世界上第一个可计算存储 PCIe SSD(命名为 CSD 2000),它在内部对 I/O 路径上的每个 4KB 数据块进行 zlib(解)压缩,对主机透明。它的详细信息在官网博客中有所介绍。
乍一看,人们可能会认为这种存储内透明压缩的全部好处是透明地降低存储成本和透明地提高
IOPS,仅此而已。事实上,这只是最初的想法。随着进一步的研究,我们逐渐意识到这远不是存储透明压缩的全部好处。除了明显的成本和
IOPS 优势之外,透明压缩为非常令人兴奋的系统级创新机会打开了一扇门,虽然这块领域在很大程度上还未被开发。我们将介绍可以展示创新潜力的案例研究。
传统定长块I/O设计问题
所有数据存储驱动器(例如
SSD、
HDD、光盘和磁带)都作为块设备运行,其中数据通过标准块
I/O 接口协议(例如
NVMe 和 SATA)以固定大小的块(多是 4KB)为单位进行访问。当使用普通存储驱动器(即那些没有内置透明压缩的驱动器)时,计算系统(指文件系统)设计目标很自然在每个 4KB 定长块里填充有用的数据以降低存储成本,以最小化存储成本。众所周知,定长块
I/O 对数据管理软件(例如,关系数据库、键值存储、对象存储和文件系统)的设计有一些严格的限制。例如,为了容纳定长块
I/O,
B+ 树被迫设计所有节点的大小都是文件系统定长块的倍数,并尽可能满地填充每个树节点,这在理论上可能不是最优的。与此形成鲜明对比的是,通过存储内透明压缩,我们不再要求应用尽可能有效使用(用完)每个定长块,因为任何应用未使用的空间都可以在可计算存储内部被压缩掉。因此,应用可以在 4KB 定长块 I/O 中写任意大小的数据(例如
2KB、
1KB 甚至
100B)。这实现了
实际变长的块
I/O。这意思是,即使我们仍然遵守现有协议(如NVMe或SATA)定长块 I/O 接口,每个块包含的有用数据可以是可变大小,同时实际物理存储成本也不会受到影响。这实质上打破了传统的定长块
I/O 约束。上述讨论可以在图
1 中进一步说明。
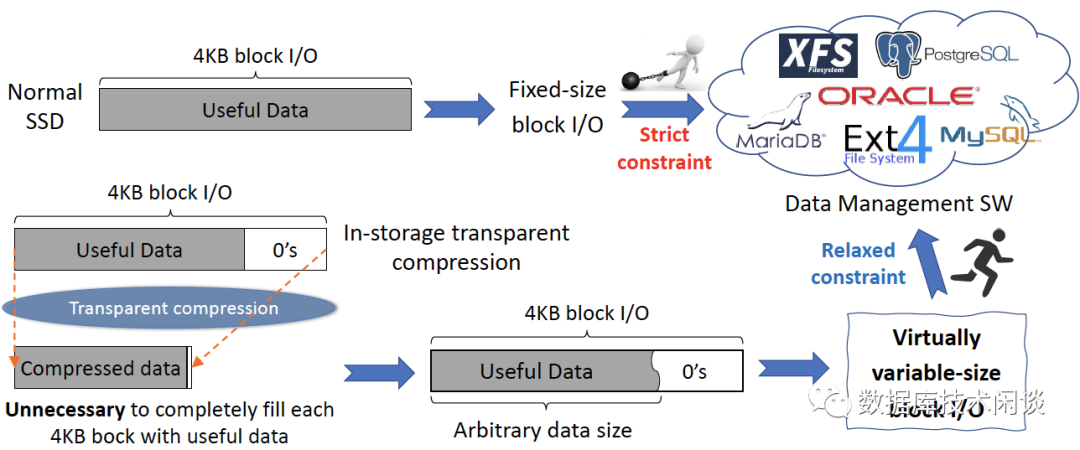
图 1:存储中透明压缩启用的实际变长的块 I/O 的图示。
在过去的 40 年里,所有数据管理软件基础设施都是基于定长块块 I/O 约束构建的。直观地说,随着存储中透明压缩支持的实际变长的块 I/O 的到来,也迎来了重新思考数据管理软件(主要指数据库)的设计和执行的机会。在这种情况下,如图 2 所示,所有创新和修改都完全限制在用户应用程序域内,而整个 I/O 堆栈保持不变。显然,它可以大大降低开发成本和使用障碍,这是终端用户非常希望的。
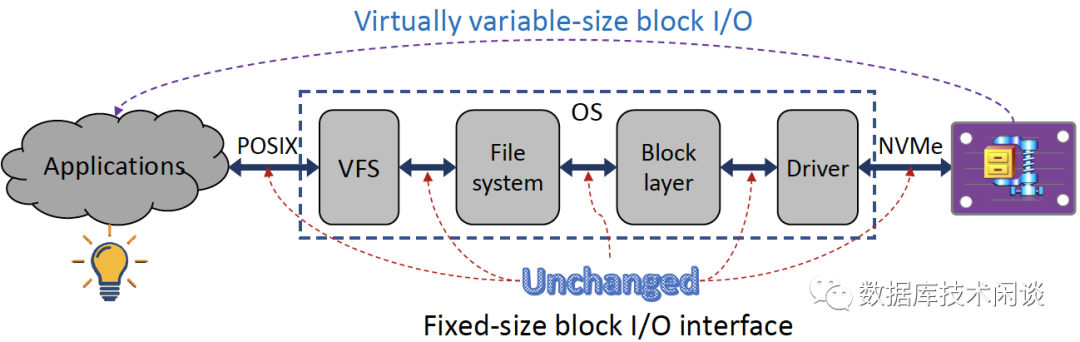
图 2:仅在用户应用程序内部进行创新,而不对 I/O 堆栈进行任何更改
根据需要应用设计改造的工作量,我们将设计进度分为三个阶段。如图 3 所示。不同的阶段意味着不同的开发成本和不同的收益。它们共同构成了基础设施软件创新的令人兴奋的新前沿。在后面,我们将介绍这三个阶段的一些案例研究,希望这些研究有助于吸引更多的开发者进入这个令人兴奋但很大程度上尚未开发的领域。
这些案例都有一个共同点 ,当运行在可计算存储 CSD 上时,应用软件可以维持原有的定长块 I/O 设计且不用刻意节省空间(逻辑空间 LBA )而达到既提升性能又不会浪费真实的物理空间(PBA)的双赢目标。

图 3:整个软件创新设计进度的图示。
PostgreSQL 的 Fillfactor 问题
作为应用最广泛的关系型数据库之一,PostgreSQL 用 B+ tree 管理其数据存储(默认B+ Tree 页大小为8KB),通过在表里存储行的多个版本实现 MVCC(多版本并发控制)。因此,当需要更新记录时,PostgreSQL 没有直接更新当前行,而是在新的位置写入行最新版本的记录,并依赖于后台 vacuum 进程来回收老的不用的版本数据所占用的表空间。因此,PostgreSQL 更新操作的 TPS 性能很大程度上取决于 PostgreSQL 是否可以将新版本记录存储在与老版本记录相同的页面中:
-
如果存储旧版本行记录的页面满了,则 PostgreSQL 必须将新版本行存储在另一个页面中。因此,PostgreSQL 必须修改 B+ Tree 结构里一个或多个页(分配新的页或分裂老的页)。这将导致额外的CPU 消耗和 TPS 性能下降。
-
如果存储旧版本行记录的页面有足够的剩余空间,那么 PostgreSQL 只需在该页中添加新版本行记录。通过保持 B+ Tree 结构的完整,维持很低的 CPU 利用率,从而提高 TPS 性能。
上面揭示了提升 TPS 性能和降低存储空间之间的平衡思路:当将数据加载到 PostgreSQL 时,如果不完全填充 B+ Tree 页,预留一部分剩余余空间来容纳之后的更新,这样可以提高 TPS 的性能。然而,这同时增加了更多的 B+ Tree 页,从而消耗了更多的存储空间。如图 4 所示,PostgreSQL 允许用户通过使用一个名为填充因子(Fill Factor)的参数配置来实现这样的平衡。通过在10到100之间调整填充因子的百分比,来控制B+ Tree 页填充量。它的默认值是 100,即每个页面可能都写满了新增的行,就不会为之后的更新预留任何空间。

图 4:PostgreSQL使用参数 Fillfactor 来配置 TPS 性能与存储成本的权衡。
当
PostgreSQL 在普通的
SSD/HDD 上运行时,无论一个页是否写满有用的数据,该页都要消耗
8KB 的物理存储空间。Fillfactor 参数就成为 TPS 性能和存储空间直接权衡的关键。正如前面提到,存储内的透明压缩可以在使用
4KB 块 I/O 接口的情况下支持实际变长的块
I/O。因此,当
PostgreSQL 在具有内置透明压缩的存储驱动器上运行时,一个页面的用户数据填充量能直接决定该页面所消耗的物理存储空间。这可以在很大程度上实现了
PostgreSQL在
TPS 性能与存储成本之间的平衡。也就是说,当我们降低
Fillfactor 的值,为每个页面之后的更新预留更多的空间时,实际物理存储使用不会成比例增加。因此,通过支持实际变长的块
I/O,存储内透明压缩允许
PostgreSQL 充分降低填充因子,以在不牺牲物理存储成本的前提下提高
TPS 性能。
为了进一步验证这一设想,我们使用
Percona 序列台
-TPCC OLTP基准测试在
PostgreSQL 上进行了实验。我们使用了一个具有
32核
3.3GHz Xeon CPU 的服务器,然后考虑了两种不同的数据集大小:
740GB 和
1.4TB,并在一个普通的
NVMe SSD 和
CSD2000 上进行了实验(
64个客户端线程)。图 5
显示了将填充因子分别设置为
100 和
75 时,
TPS 性能和物理存储空间使用情况。在相同的填充因子下,
PostgreSQL 在普通的
NVMe SSD 和我们的
CSD2000 上实现了相同的
TPS 。当将填充因子从
100 减少到
75 时,
TPS 性能均提高了约
33% 。在
740GB 数据集,
Fillfactor 配置为
100 下,CSD 内透明压缩可以将物理存储使用从
740GB 减少到
178GB 。当将
Fillfactor 从
100 减少到
75 时,普通
NVMe SSD上的物理存储使用率按比例从
740GB 增加到
905GB,而
CSD2000 上的物理存储使用仅从
178GB 略微增加到
189GB 。在
1.4TB 数据集的结果上也可以观察到类似的现象。实验结果清楚地表明,通过简单地配置
Fillfactor 参数,
PostgreSQL 可以从 CSD 的透明压缩中显著获益,而无需改变任何源代码。

图 5:当 PostgreSQL 在CSD2000 和普通 NVMeSSD 上运行时,不同 Fillfactor 下的标准化TPS性能与不同填充因子下的物理存储使用情况。
WAL 日志的写放大问题
数据库和文件系统几乎普遍使用预写日志(WAL, Write Ahead Logging) 来确保原子性操作和数据持久性。它的基本概念非常简单:在应用到数据文件之前,数据修改会被保存到一个专用的日志区域。在一般情况中,数据修改首先在内存 WAL 缓冲区中以日志形式暂存,然后刷新到 WAL 日志文件中(存储里)。为了最大限度地提高数据持久性,系统会在每次事务提交时执行 WAL 日志文件强制刷盘逻辑(使用 fsync 或 fdatasync 等命令)。为了减少日志引起的存储成本,传统做法总是将日志记录先暂存到内存中的 WAL 缓冲区中,然后再批量写到 WAL 日志文件中。因此,多个连续的 WAL缓冲区刷新可能会写入存储设备上的同一个4KB LBA 块中,尤其是当事务记录明显小于 4KB 或者工作负载并发性不高时。
这可以在图 6 中说明:假设三个事务 TRX-1、TRX-2 和 TRX-3(具有日志记录 L1、L2 和 L3)分别在时间 t1、t2 和 t3 提交。如图 1 所示,在时间 t1,4K 数据 [L1, 0] 从内存中的 WAL 缓冲区刷新到存储设备上的LBA 0x0001,其中 0 表示空数据(\0)。稍后,日志记录 L2 被附加到 WAL 缓冲区中,并且在时间 t2,4KB 数据 [L1, L2, 0] 被刷新到存储设备上相同的 LBA 0x0001。类似地,在时间 t3,4KB 数据 [L1, L2, L3, 0] 被刷新到存储设备上相同的 LBA 0x0001。如图1所示,相同的日志记录(例如,L1 和 L2)被多次写入 NAND 闪存,导致写放大。众所周知,写放大直接导致更短的闪存寿命和更低的存储 IOPS 性能。可以通过简单地禁用或者降低每次事务提交刷新频率来减少WAL引起的写放大,但这不再能够保证最近提交事务的数据持久性(故障时会丢数据)。
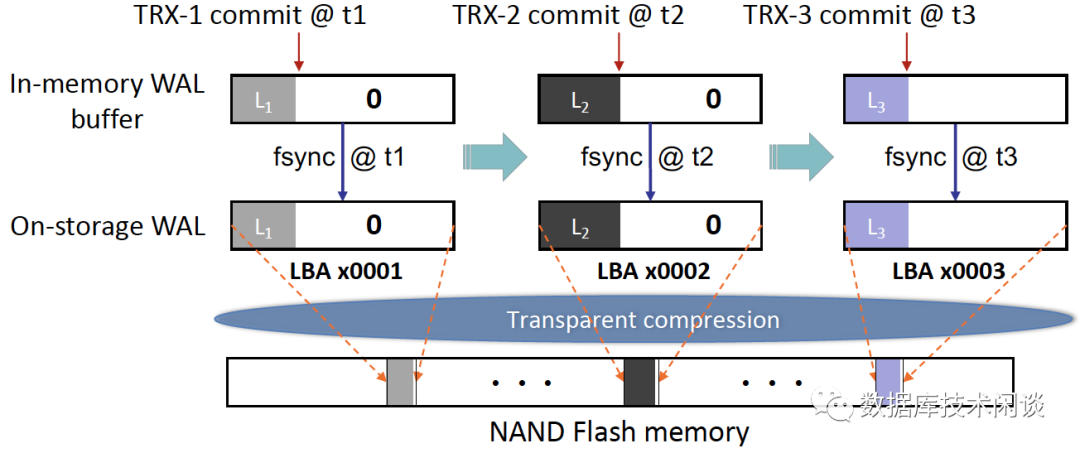
图 6:传统的 WAL 实现,其中日志记录被暂存到 WAL 中,连续的事务提交可能多次将数据刷新到同一个 LBA 块(例如,本例中的LBA 0x0001)。
利用 CSD 透明压缩带来的支持变长块 I/O 能力,我们可以使用一种稀疏日志的技术,在不牺牲数据持久性的情况下,来显著减少 WAL 引起的写放大。它的基本想法也很简单:在每次事务提交时,总是将空(0x0)填充到内存中的 WAL 缓冲区中,使其内容按 4KB 对齐。因此,下一条日志记录将写入WAL缓冲区中新的 4KB 空间。因此,每条日志记录在刷盘时只会写入一次 NAND 闪存。与传统做法相比,这样可以显著减少写入放大。
这可以在图 7 中进一步说明:假设与上面图 1 所示的场景相同,事务 TRX-1 在时间 t1 提交后,我们将空(0x0)填充到 WAL 缓冲区并刷新 4K 数据 [L1, 0 ] 到存储设备上的 LBA 0x0001 。随后,我们将下一条日志记录 L2 放在 WAL 缓冲区中新的 4KB 空间中。在时间 t2,4KB 数据 [L2, 0] 被刷新到存储设备上新的 LBA 0x0002 。类似地,在时间 t3,4KB 数据 [L3, 0] 被刷新到存储设备上的另一个新的 LBA 0x0003 。显然,每个日志记录只写入一次 NAND 闪存。同时,每个稀疏 4KB 块中的所有位空(0x0)的数据都被存储中透明压缩给压缩掉。与传统做法相比,这会导致较小的 WAL 引起的写入放大。

图 7:CSD 透明压缩启用的稀疏日志方法的说明,其中每个 WAL 刷新始终写入存储设备上的新的 LBA block
参考
感兴趣的请参考下面文章。
-
Closing the B+-tree vs. LSM-tree Write Amplification Gap on Modern Storage Hardware with Built-in Transparent Compression
-
KallaxDB: A Table-less Hash-based Key-Value Store on Storage Hardware with Built-in Transparent Compression
-
POLARDB Meets Computational Storage - Efficiently Support Analytical Workloads in Cloud-Native Relational Database