首先如果是 maven 项目的话需要添加以下依赖,普通项目的话在官网( http://itextpdf.com/ )下载对应的jar包加入即可。若是maven项目,添加依赖如下:
com.itextpdf itextpdf 5.4.3 net.sf.barcode4j barcode4j 2.1
操作工具类1:
package com.hong.webTest.common.util;
import com.itextpdf.text.*;
import com.itextpdf.text.pdf.*;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import java.io.ByteArrayOutputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @Description 可实现单个PDF模板重复使用生成同一个PDF文件
* @Author
* @Date
* @Version 1.0
**/
// @Slf4j
public class PdfUtil {
/**
* 模板阅读器
*/
private String templatePath;
/**
*
*/
private List outList;
/**
* 基准字体
*/
private BaseFont bf;
/**
* 创建PDF处理对象
* @param templatePath
* @param fontPath
* @return
*/
@SneakyThrows
public static PdfUtil create(String templatePath,String fontPath){
PdfUtil pdf = new PdfUtil();
// 读取pdf模板
pdf.templatePath = templatePath;
pdf.bf = BaseFont.createFont(fontPath , BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
return pdf;
}
/**
* 获取结果
* @return
*/
@SneakyThrows
public ByteArrayOutputStream getOutputStream(){
if (outList == null) {
return null;
}
Document doc = new Document();
ByteArrayOutputStream out = new ByteArrayOutputStream();
PdfCopy copy = new PdfCopy(doc, out);
doc.open();
for (byte[] array:outList) {
PdfReader reader = new PdfReader(array);
for (int i = 1; i <= reader.getNumberOfPages(); i++) {
PdfImportedPage importPage = copy.getImportedPage(reader,i);
copy.addPage(importPage);
}
reader.close();
}
doc.close();
return out;
}
@SneakyThrows
public void copyPage(Map strMap, Map imgMap){
ByteArrayOutputStream bos = new ByteArrayOutputStream();
PdfReader reader = new PdfReader(templatePath);
PdfStamper stamper = new PdfStamper(reader, bos);
AcroFields form = stamper.getAcroFields();
//文字类的内容处理
form.addSubstitutionFont(bf);
strMap.forEach((k,v)->{
try {
form.setField(k,v);
} catch (Exception e) {}
});
// 图片类的内容处理
imgMap.forEach((k,v)->{
try {
int pageNo = form.getFieldPositions(k).get(0).page;
Rectangle signRect = form.getFieldPositions(k).get(0).position;
float x = signRect.getLeft();
float y = signRect.getBottom();
//读取图片
Image image = v;
//获取图片页面
PdfContentByte under = stamper.getOverContent(pageNo);
//图片大小自适应
image.scaleToFit(signRect.getWidth(), signRect.getHeight());
//添加图片
image.setAbsolutePosition(x, y);
under.addImage(image);
} catch (Exception e) {}
});
// 如果为false,生成的PDF文件可以编辑,如果为true,生成的PDF文件不可以编辑
stamper.setFormFlattening(true);
stamper.close();
reader.close();
if (outList == null){
outList = new ArrayList<>(8);
}
outList.add(bos.toByteArray());
}
/*public static void main(String[] args) throws IOException {
PdfUtil pdfUtil = PdfUtil.create("static/temp/code.pdf", "static/fonts/simhei.ttf");
for (int i = 0; i < 10; i++) {
Map map = new HashMap();
map.put("local","0101013A0"+i);
map.put("count","第 "+i+" 次");
map.put("boxNo","201901010407600009"+i);
map.put("deptCode","01010407"+i);
map.put("deptName","雁塔支行");
map.put("actCount",i+"");
Map map1 = new HashMap();
map1.put("code",Image.getInstance(BarCodeUtil.getInstanceImage("201901010407600009"+i)));
pdfUtil.copyPage(map,map1);
}
ByteArrayOutputStream outputStream = pdfUtil.getOutputStream();
FileOutputStream fileOutputStream = new FileOutputStream("G:/Test/code123.pdf");
fileOutputStream.write(outputStream.toByteArray());
fileOutputStream.close();
}*/
}
操作工具类2:
package com.hong.webTest.common.util;
import com.itextpdf.text.Document;
import com.itextpdf.text.Image;
import com.itextpdf.text.Rectangle;
import com.itextpdf.text.pdf.*;
import lombok.SneakyThrows;
import java.io.ByteArrayOutputStream;
import java.util.Map;
/**
* @Description 单个模板单个生成
* @Author
* @Date
* @Version 1.0
**/
public class PdfUtil1 {
@SneakyThrows
public static byte[] pdfCreate(String templatePath, String fontPath, Map strMap, Map imgMap){
ByteArrayOutputStream bos = new ByteArrayOutputStream();
PdfReader reader = new PdfReader(templatePath);
PdfStamper stamper = new PdfStamper(reader, bos);
AcroFields form = stamper.getAcroFields();
//文字类的内容处理
BaseFont bf = BaseFont.createFont(fontPath , BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
form.addSubstitutionFont(bf);
strMap.forEach((k,v)->{
try {
form.setField(k,v);
} catch (Exception e) {}
});
// 图片类的内容处理
imgMap.forEach((k,v)->{
try {
int pageNo = form.getFieldPositions(k).get(0).page;
Rectangle signRect = form.getFieldPositions(k).get(0).position;
float x = signRect.getLeft();
float y = signRect.getBottom();
//读取图片
Image image = v;
//获取图片页面
PdfContentByte under = stamper.getOverContent(pageNo);
//图片大小自适应
image.scaleToFit(signRect.getWidth(), signRect.getHeight());
//添加图片
image.setAbsolutePosition(x, y);
under.addImage(image);
} catch (Exception e) {}
});
// 如果为false,生成的PDF文件可以编辑,如果为true,生成的PDF文件不可以编辑
stamper.setFormFlattening(true);
stamper.close();
reader.close();
Document doc = new Document();
ByteArrayOutputStream out = new ByteArrayOutputStream();
PdfCopy copy = new PdfCopy(doc, out);
doc.open();
PdfReader pdfReader = new PdfReader(bos.toByteArray());
for (int i = 1; i <= pdfReader.getNumberOfPages(); i++) {
PdfImportedPage importPage = copy.getImportedPage(pdfReader, i);
copy.addPage(importPage);
}
pdfReader.close();
doc.close();
return out.toByteArray();
}
}
PDF模板制作
模板制作
1.先用word制作原型模板,如:

制作好后另存为PDF文件。
2.利用Adobe Acrobat X Pro打开原型PDF,制作PDF模板
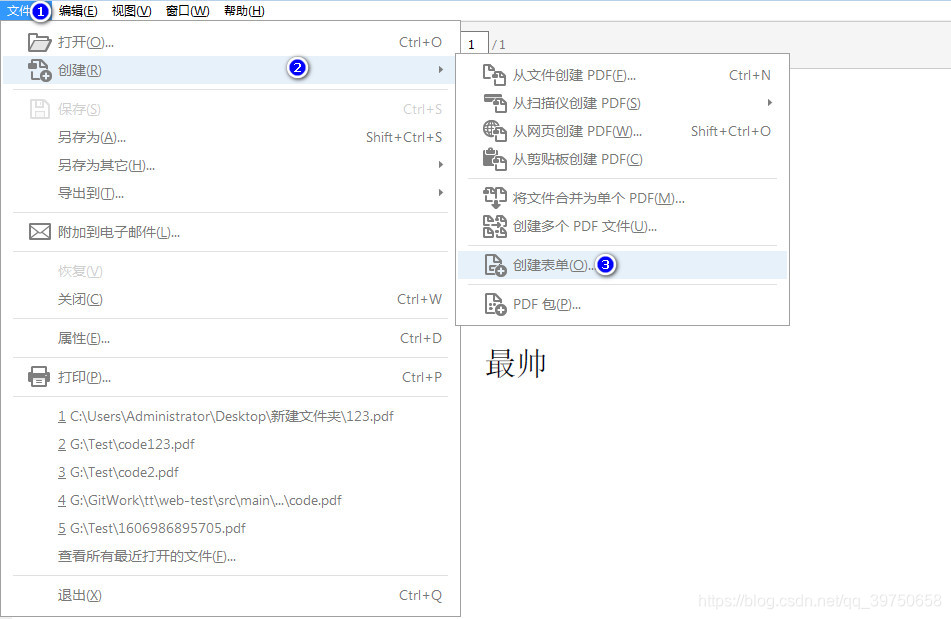
依次点击 文件>>创建>>创建表单>>选择本文件>>确认
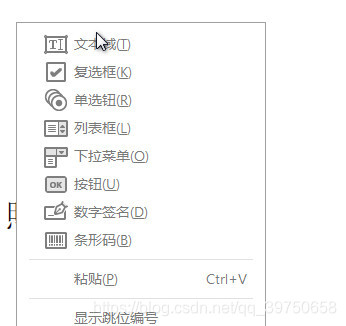
右键增加文本域并设置key值
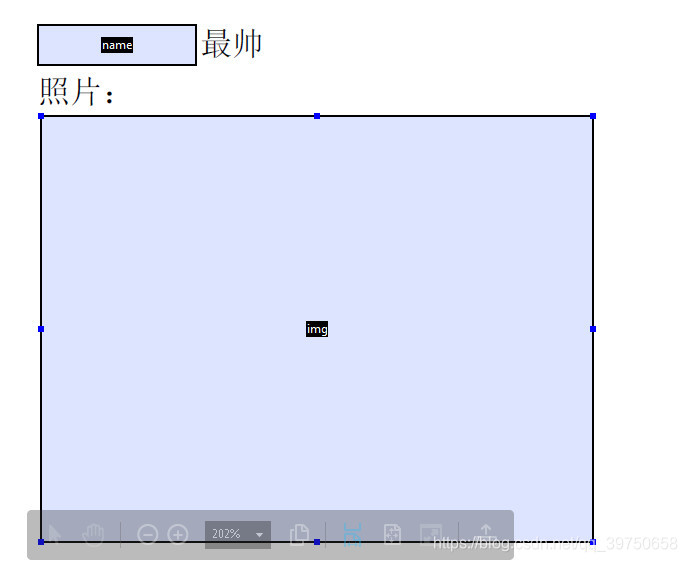
保存后,模板制作完成。