《Thinking in Java》第18章的内容是相当丰富精彩的,也在网络学习参考了很多前辈们的笔记,个人由于能力有限(毕竟和大神Bruce Eckel的能力相差甚远),将这一章的内容分三个部分来写,希望能够慢慢品味和领悟Java IO的精粹:
第一部分、字节流和字符流,可以认为是传统的Java IO;
第二部分、新IO,指JDK 1.4引入的java.nio.*类库;
第三部分、Java序列化和反序列化技术,包括了对象序列化、XML等内容。
当然,笔者的能力相当有限,纯属一个菜鸟做得笔记,希望各位前辈不吝赐教!言归正传,本篇主要讲Java IO的字节流和字符流,章节安排如下:
-
起步:File类
-
字节流和字符流概述
-
装饰者模式(Decorator)和适配者模式(Adapter)
-
基于字节流的IO操作
-
基于字符流的IO操作
1. 起步:File类
令我很吊胃口的一件事情是,当我翻开圣经,想拜读Java IO的精髓时,Eckel告诉我,在学习真正用于流读写数据的类之前,让我们先学习如何处理文件目录问题(潜台词仿佛在说,对不起,菜鸟,你得从基础班开始!)
File类:Java中File既能代表一个特定文件的名称,又能代表一个目录下的一组文件(相当于Files)
我们要学会的是,如何从一个目录下筛选出我们想要的文件?可以通过目录过滤器FilenameFilter+正则表达式实现对文件的筛选:
import java.io.File; import java.io.FilenameFilter; import java.util.Arrays; import java.util.regex.Pattern; /**
* 目录过滤器
* 显示符合条件的File对象
* @author 15070229
*
*/ class DirFilter implements FilenameFilter { private Pattern pattern; public DirFilter (String regex) {
pattern = pattern.compile(regex);
} public boolean accept(File dir, String name) { return pattern.matcher(name).matches();
}
} public class DirList { public static void main(String[] args) {
File path = new File(".");
String[] list; if(args.length == 0)
list = path.list(); else list = path.list(new DirFilter(args[0]));
Arrays.sort(list, String.CASE_INSENSITIVE_ORDER); for(String dirItem: list)
System.out.println(dirItem);
}
}
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
这个用匿名内部类的方式来实现是更合适的,DirFilter在内部实现,使程序变的更小巧灵活:
* 通过内部类方式实现的目录列表器
*/ package c18; import java.io.File; import java.io.FilenameFilter; import java.util.Arrays; import java.util.regex.Pattern; public class DirList2 { public static FilenameFilter filter(final String regex) { return new FilenameFilter() { private Pattern pattern = Pattern.compile(regex); @Override public boolean accept(File dir, String name) { return pattern.matcher(name).matches();
}
};
} public static void main(String[] args) {
File path = new File(".");
String[] list; if(args.length == 0)
list = path.list(); else list = path.list(new DirFilter(args[0]));
Arrays.sort(list, String.CASE_INSENSITIVE_ORDER); for(String dirItem: list)
System.out.println(dirItem);
}
}
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
针对一些文件集上的常用操作我们可以封装成一个工具类,比如:
/**
* 目录实用工具类
* 本地目录操作:local方法产生经过正则表达式筛选的本地目录的文件数组
* 目录树操作:walk方法产生给定目录下的由整个目录树中经过正则表达式筛选的文件构成的列表
*/ package c18; import java.io.File; import java.io.FilenameFilter; import java.util.ArrayList; import java.util.Arrays; import java.util.Collection; import java.util.Iterator; import java.util.List; import java.util.regex.Pattern; public final class Directory { /**
* 根据正则表达式,筛选产生File数组
* @param dir
* @param regex
* @return */ public static File[] local(File dir, final String regex) { return dir.listFiles(new FilenameFilter() { private Pattern pattern = Pattern.compile(regex); @Override public boolean accept(File dir, String name) { return pattern.matcher(name).matches();
}
});
} public static File[] local(String path, final String regex) { return local(new File(path), regex);
} public static class TreeInfo implements Iterable<File> { public List files = new ArrayList(); public List dirs = new ArrayList(); public Iterator iterator() { return files.iterator();
} void addAll(TreeInfo other) {
files.addAll(other.files);
dirs.addAll(other.dirs);
} public String toString() { return "dirs:" + PPrint.pformat(dirs) + "\n\nfiles: " + PPrint.pformat(files);
}
} /**
* 遍历目录
* @param start
* @param regex
* @return */ public static TreeInfo walk(String start, String regex) { return recurseDirs(new File(start), regex);
} public static TreeInfo walk(File start, String regex) { return recurseDirs(start, regex);
} public static TreeInfo walk(File start) { return recurseDirs(start, ".*");
} public static TreeInfo walk(String start) { return recurseDirs(new File(start), ".*");
} /**
* 递归遍历文件目录,收集更多的信息(区分普通文件和目录)
* @param startDir
* @param regex
* @return */ static TreeInfo recurseDirs(File startDir, String regex) {
TreeInfo result = new TreeInfo(); for(File item : startDir.listFiles()) { if (item.isDirectory()) { result.dirs.add(item);
} else if(item.getName().matches(regex)) result.files.add(item);
} return result;
} public static void main(String[] args) { PPrint.pprint(Directory.walk(".").dirs); for(File file : Directory.local(".", "T.*"))
System.out.println(file);
}
} /**
- 格式化打印机,打印格式如下:
- [
- .\.settings
- .\bin
- .\src
- ]
*/ class PPrint { public static String pformat(Collection c) { if(c.size() == 0) return "[]";
StringBuilder result = new StringBuilder("["); for(Object elem : c) { if(c.size()!=1)
result.append("\n ");
result.append(elem);
} if(c.size()!=1)
result.append("\n ");
result.append("]"); return result.toString();
} public static void pprint(Collection c) {
System.out.println(pformat(c));
} public static void pprint(Object c) {
System.out.println(Arrays.asList(c));
}
}
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
-
54
-
55
-
56
-
57
-
58
-
59
-
60
-
61
-
62
-
63
-
64
-
65
-
66
-
67
-
68
-
69
-
70
-
71
-
72
-
73
-
74
-
75
-
76
-
77
-
78
-
79
-
80
-
81
-
82
-
83
-
84
-
85
-
86
-
87
-
88
-
89
-
90
-
91
-
92
-
93
-
94
-
95
-
96
-
97
-
98
-
99
-
100
-
101
-
102
-
103
-
104
-
105
-
106
-
107
-
108
-
109
-
110
-
111
-
112
-
113
-
114
-
115
-
116
-
117
-
118
-
119
-
120
-
121
-
122
-
123
-
124
-
125
-
126
-
127
-
128
-
129
-
130
-
131
-
132
-
133
-
134
-
135
2. 字节流和字符流概述
Java IO中处理字节流和字符流输入输出的基类和派生类繁多,本节主要做两件事情:(1)给出类的关系图;(2)回答一个问题,为什么字节流和字符流要分开处理,为什么既要有Reader/Writer,又保留InputStream/OutputStream?
字节流和字符流输入输出的基类和派生类的关系图如下所示:(图片来源于网络,笔者想吐槽这张关系图太难画了,废了半小时力气最终还是放弃了,可见JAVA IO类关系的复杂性)
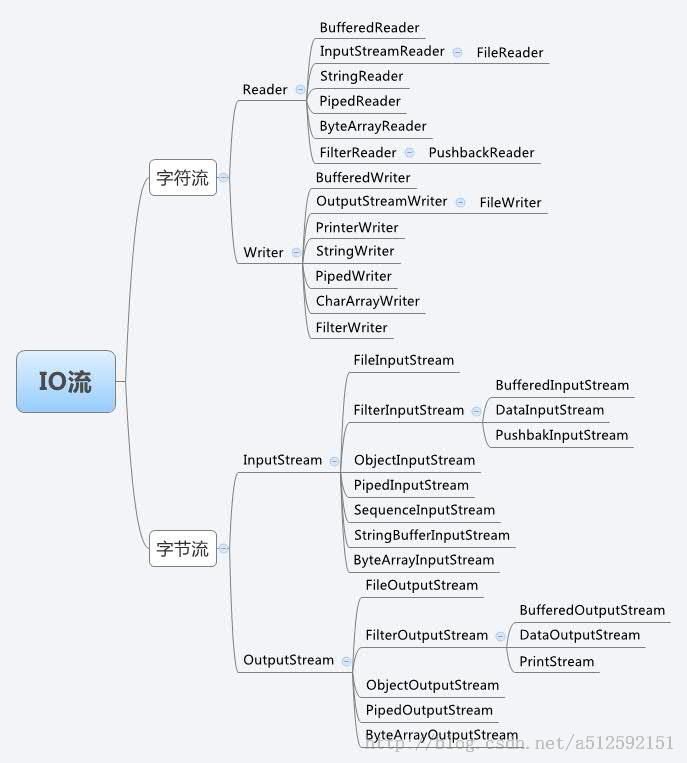
Java 1.0中是只存在InputStream/OutputStream的,设计Reader/Writer 主要是为了国际化需要。老的IO结构设计仅支持8位字节流,并且不能很好地处理16位的Unicode字符。由于Unicode用于字符国际化,因此添加了Reader/Writer。
那为什么还要继续使用InputStream/OutputStream,二者的用处是不一样的,有些时候使用InputStream/OutputStream才能得到正确的结果:
-
字节流可用于任何类型的对象,包括二进制对象(典型场景包括图片压缩、文件下载等),而字符流只能处理字符或者字符串
-
字节流提供了处理任何类型的IO操作的功能,但它不能直接处理Unicode字符,而字符流就可以
-
字节流在操作的时候本身是不会用到缓冲区(内存)的,是与文件本身直接操作的(最原始的字节流没有用到缓冲区,但是你可以给它套一个缓冲流BufferedInputStream/BufferedOutputStream),而字符流在操作的时候是使用到缓冲区的
所以,不同的场景下究竟是使用字节流还是字符流就体现了一个程序员对Java的理解程度了。
3. 装饰者模式和适配器模式
Java IO中分别用到了装饰者模式和适配者模式。
装饰者模式(Decorator)
装饰模式(Decorator)又称为包装模式(Wrapper),通过创建一个装饰(包装)对象,来装饰真实的对象。
Java I/O类库需要多种不同功能的组合,这正是使用装饰器模式的理由所在。为什么不使用继承而采用装饰器模式呢?如果说Java IO的各种组合是通过继承方式来实现的话,那么每一种组合都需要一个类,这样就会出现大量重复性的问题。而通过装饰器来实现组合,恰恰避免了这个问题。
对于字节流而言,FilterInputStream和FilterOutputStream是用来提供装饰器接口以控制特定输入\输出的两个类。需要注意的是,对于字符流而言,同样用到的是装饰者模式,但是有一点不同,Reader体系中的FilterRead类和InputStream体系中的FilterInputStream的功能不同,它不再是装饰者。
这一点可以从BufferReader和BufferStreamReader的实现不同可以看出。
BufferReader:public class BufferedReader extends Reader BufferedInputStream:public class BufferedInputStream extends FilterInputStream
举一个例子如下所示,其中BufferedReader是装饰对象,FileReader是被装饰对象。
package c18; import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; public class BufferedInputFile { public static String read(String filename) throws IOException{ BufferedReader in = new BufferedReader(new FileReader(filename));
String s;
StringBuilder sb = new StringBuilder(); while ((s = in.readLine())!=null) {
sb.append(s + "\n");
}
in.close(); return sb.toString();
}
}
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
适配者模式(Adapter)
适配者模式又可以分为类适配方式(类似多继承)和对象适配方式。而Java IO中使用的是对象适配方式。我们以FileOutputStream为例,可以看到源码中,FileOutputStream继承了OutputStream类型,同时持有一个对FileDiscriptor对象的引用。这是一个将FileDiscriptor接口适配成OutputStream接口形式的对象形适配器模式。
public class FileOutputStream extends OutputStream { private FileDescriptor fd; public FileOutputStream(FileDescriptor fdObj) {
SecurityManager security = System.getSecurityManager(); if (fdObj == null) { throw new NullPointerException();
} if (security != null) {
security.checkWrite(fdObj);
}
fd = fdObj;
fd.incrementAndGetUseCount();
}
}
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
4. 基于字节流的IO操作
本节主要介绍基于字节流的输入InputStream和输出OutputStream,以及用于实现装饰模式的FilterInputStream和FilterOutputStream。
InputStream的作用是表示从不同数据源产生输入的类:
-
字节数组
-
String对象
-
文件
-
管道
-
一个由其他种类的流组成的序列
-
其他数据源
下面列表展现了InputStream的派生类,所有的派生类都要联合装饰类FilterInputStream 组合使用:
-
作用: 允许将内存的缓冲区作为输入
-
构造器参数:字节将从缓冲区中取出
/**
* Creates a ByteArrayInputStream
* so that it uses buf as its
* buffer array.
* The buffer array is not copied.
* The initial value of pos
* is 0 and the initial value
* of count is the length of
* buf.
*
* @param buf the input buffer.
*/ public ByteArrayInputStream(byte buf[]) { this.buf = buf; this.pos = 0; this.count = buf.length;
}
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
举个例子:
/**
* 格式化内存输出
*/ package c18; import java.io.ByteArrayInputStream; import java.io.DataInputStream; import java.io.EOFException; import java.io.IOException; public class FormattedMemoryInput { public static void main(String[] args) throws IOException{ try { DataInputStream in = new DataInputStream( new ByteArrayInputStream( BufferedInputFile.read("D:/workspace/java_learning/" + "Java_Learning/src/c18/DirList2.java").getBytes())); while (true) { System.out.println((char)in.readByte());
}
} catch (EOFException e) {
System.err.println("End of stream");
}
}
}
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
作用:将String作为输入
-
构造器参数:String
需要注意的是StringBufferInputStream已经过时了,JDK给出的过时原因如下:
This class does not properly convert characters into bytes. As of JDK 1.1, the preferred way to create a stream from a string is via the StringReader class.
StringBufferInputStream 已经不再适合将字符转化为字节,更优的选择是通过StringReader将字符转化为流。
-
作用:用于从文件中读取信息
-
构造器参数:表示文件路径的字符串、File对象、FileDescriptor对象
public FileInputStream(String name) throws FileNotFoundException { this(name != null ? new File(name) : null);
} public FileInputStream(File file) throws FileNotFoundException {
String name = (file != null ? file.getPath() : null);
SecurityManager security = System.getSecurityManager(); if (security != null) {
security.checkRead(name);
} if (name == null) { throw new NullPointerException();
}
fd = new FileDescriptor();
fd.incrementAndGetUseCount();
open(name);
} public FileInputStream(FileDescriptor fdObj) {
SecurityManager security = System.getSecurityManager(); if (fdObj == null) { throw new NullPointerException();
} if (security != null) {
security.checkRead(fdObj);
}
fd = fdObj;
fd.incrementAndGetUseCount();
}
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
作用:产生写入PipedOutputStream中的数据,实现“管道化”
-
构造器参数:PipedOutputStream
public PipedInputStream(PipedOutputStream src, int pipeSize) throws IOException {
initPipe(pipeSize);
connect(src);
}
管道流可以实现两个线程之间,二进制数据的传输。管道流就像一条管道,一端输入数据,别一端则输出数据。通常要分别用两个不同的线程来控制它们。(这里埋个伏笔,目前笔者对多线程掌握还不够成熟,等到后面学习Java并发中会继续提到PipedIntputStream/PipedOutputStream)
-
作用:将两个或多个InputStream对象转换成单一InputStream
-
构造器参数:两个InputStream或一个容器Enumeration
public SequenceInputStream(Enumeration e) { this.e = e; try {
nextStream();
} catch (IOException ex) { throw new Error("panic");
}
} public SequenceInputStream(InputStream s1, InputStream s2) {
Vector v = new Vector(2);
v.addElement(s1);
v.addElement(s2);
e = v.elements(); try {
nextStream();
} catch (IOException ex) { throw new Error("panic");
}
}
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
举两个例子(源于网络):
import java.io.*; import java.util.*;
class SequenceDemo1
{ public static void main(String[] args)throws IOException
{
Vector v = new Vector();
v.add(new FileInputStream("c:\\1.txt"));
v.add(new FileInputStream("c:\\2.txt"));
v.add(new FileInputStream("c:\\3.txt"));
Enumeration en = v.elements();
SequenceInputStream sis = new SequenceInputStream(en);
FileOutputStream fos = new FileOutputStream("c:\\4.txt"); byte[] buf = new byte[1024]; int len = 0; while((len=sis.read(buf))!=-1)
{
fos.write(buf,0,len);
}
fos.close();
sis.close();
}
}
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
import java.io.*; import java.util.*;
class SequenceDemo2
{ public static void main(String[] args)throws IOException
{
InputStream is1 = null;
InputStream is2 = null;
OutputStream os = null;
SequenceInputStream sis = new null;
is1 = new FileInputStream("d:"+File.separator+"a.txt");
is2 = new FileInputStream("d:"+File.separator+"b.txt");
os = new FileOutputStream("d:"+File.separator+"ab.txt");
sis = new SequenceInputStream(is1,is2); int temp = 0; while((temp)=sis.read()!=-1)
{
os.write(temp);
}
sis.close();
is1.close();
is2.close();
os.close();
}
}
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
另外,还有FilterInputStream,它是抽象类,作为“装饰器”的接口,笔者将单独用一节来详述。
字节流输出OutputStream
OutputStream的作用是表示从不同数据源产生输入的类:
下面是OutputStream的派生类。同样,所有的派生类都要联合装饰类FilterOutputStream 组合使用。
ByteArrayOutputStream
与ByteArrayInputStream相对应,
- 作用:在内存中创建缓冲区,所有送往“流”的数据都要放置在此缓冲区
- 构造器参数:缓冲区初始化尺寸(可选的)
public ByteArrayOutputStream() { this(32);
} public ByteArrayOutputStream(int size) { if (size < 0) { throw new IllegalArgumentException("Negative initial size: " + size);
}
buf = new byte[size];
}
FileOutputStream
与FileInputStream相对应,
- 作用:将信息写至文件
- 构造器参数:表示文件路径的字符串、File对象、FileDescriptor对象
PipedOutputStream
-
作用:任何写入其中的信息都会自动作为相关PipedInputStream输出,实现“管道化”
-
构造器参数:PipedInputStream
FilterInputStream/FilterOutputStream同样也是InputStream/OutputStream 的派生类,但与其他派生类不同,它们是实现装饰器的抽象类。
-
作用:搭配使用,可以按照可移植的方式从流读取基本数据类型(int、char、long等)
-
构造器参数:InputStream/OutputStream
public DataInputStream(InputStream in) { super(in);
}
public DataOutputStream(OutputStream out) { super(out);
}
-
作用:使用缓冲器输入输出
-
构造器参数:InputStream/OutputStream
举个例子:
/**
* 使用缓冲区,读取二级制文件
*/ package c18; import java.io.BufferedInputStream; import java.io.File; import java.io.FileInputStream; import java.io.IOException; public class BinaryFile { public static byte[] read(File bFile) throws IOException {
BufferedInputStream bf = new BufferedInputStream( new FileInputStream(bFile)); try { byte [] data = new byte[bf.available()];
bf.read(data); return data;
} finally {
bf.close();
}
} public static byte[] read(String bFile) throws IOException { return read(new File(bFile).getAbsoluteFile());
}
}
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
作用:跟踪输入流中的行号,可调用getLineNumber()和setLineNumber(int)
-
构造器参数:InputStream
该类已经被废弃了,推荐使用字符流的类来操作。
-
作用:回推字节,读取字节,然后再将它们返回到流中。回推操作有unread()方法实现
-
构造器参数:InputStream
PushbackInputStream类实现了这一思想,提供了一种机制,可以“偷窥”来自输入流的内容而不对它们进行破坏。
public PushbackInputStream(InputStream in, int size) { super(in); if (size <= 0) { throw new IllegalArgumentException("size <= 0");
} this.buf = new byte[size]; this.pos = size;
} public PushbackInputStream(InputStream in) { this(in, 1);
}
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
package c18; import java.io.ByteArrayInputStream; import java.io.InputStream; import java.io.PushbackInputStream; public class PushbackInputStreamDemo { public static void main(String[] args) { byte[] arrByte = new byte[1024]; byte[] byteArray = new byte[]{'H', 'e', 'l', 'l', 'o',}; InputStream is = new ByteArrayInputStream(byteArray);
PushbackInputStream pis = new PushbackInputStream(is, 10); try { for (int i = 0; i < byteArray.length; i++) {
arrByte[i] = (byte) pis.read();
System.out.print((char) arrByte[i]);
} System.out.println(); byte[] b = {'W', 'o', 'r', 'l', 'd'}; pis.unread(b); for (int i = 0; i < byteArray.length; i++) {
arrByte[i] = (byte) pis.read();
System.out.print((char) arrByte[i]);
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
输出结果:
Hello
World
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
PrintStream
-
作用:PrintStream可以方便地输出各种类型的数据(而不仅限于byte型)的格式化表示形式。
-
构造器参数:InputStream
需要注意的是,与其他输出流不同, PrintStream 永远不会抛出 IOException ;它产生的IOException会被自身的函数所捕获并设置错误标记, 用户可以通过 checkError() 返回错误标记,从而查看PrintStream内部是否产生了IOException。
另外, PrintStream 提供了自动flush 和字符集设置功能 。所谓自动flush,就是往PrintStream写入的数据会立刻调用flush()函数(flush函数的作用是强制刷新缓存)。
5. 基于字符流的IO操作
设计Reader和Writer继承层次结构主要是为了国际化的16位Unicode字符编码。下表展示了Reader/Writer 和InputStream/OutputStream对应关系:
|
Java 1.0
|
Java 1.1
|
备注
|
|
InputStream
|
Reader
|
适配器:InputStreamReader
|
|
OutputStream
|
Writer
|
适配器:OutputStreamWriter
|
|
FileInputStream
|
FileReader
|
|
|
FileOutputStream
|
FileWriter
|
|
|
StringBufferInputStream
|
StringReader
|
|
|
|
StringWriter
|
|
|
ByteArrayInputStream
|
CharArrayReader
|
|
|
ByteArrayOutputStream
|
CharArrayWriter
|
|
|
PipedInputStream
|
PipedReader
|
|
|
PipedOutputStream
|
PipedWriter
|
|
|
装饰器对应关系
|
|
|
|
FilterInputStream
|
FilterReader
|
FilterReader没有子类
|
|
FilterOutputStream
|
FilterWriter
|
FilterWriter没有子类
|
|
BufferInputStream
|
BufferReader
|
BufferReader有readline()
|
|
BufferOutputStream
|
BufferWriter
|
|
|
PrintStream
|
PrintWriter
|
|
|
LineNumberInputStream
|
LineNumberReader
|
|
|
PushbackInputStream
|
PushbackReader
|
|
|
以下Java1.0类在1.1中无相应类
|
|
|
|
DataInputStream
|
|
|
|
File
|
|
|
|
RandomAccessFile
|
|
|
|
SequenceInputStream
|
|
|
举一个文件读写工具例子:
/**
* 文件读写工具
*/ package c18; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; import java.io.PrintWriter; public class TextFile { public static String read(String filename) {
StringBuilder sb = new StringBuilder(); try {
BufferedReader in = new BufferedReader(new FileReader( new File(filename).getAbsoluteFile())); try {
String s; while ((s = in.readLine())!= null) {
sb.append(s);
sb.append("\n");
}
} finally {
in.close();
}
} catch (IOException e) { throw new RuntimeException(e);
} return sb.toString();
} public static void write(String filename, String text) { try {
PrintWriter out = new PrintWriter( new File(filename).getAbsoluteFile()); try {
out.print(text);
} finally {
out.close();
}
} catch (IOException e) { throw new RuntimeException(e);
}
}
}
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
需要注意以下几点:
1. 再次强调,FilterReader/Writer是没有子类的,BufferedReader/Writer等虽然实现了装饰模式,但继承的是Reader/Writer;
2. 无论何时使用readline函数,强烈反对使用DataInputStream,推荐使用BufferedReader;
3. PrintWriter提供了PrintStream的所有打印方法。与PrintStream的区别:作为处理流使用时,PrintStream只能封装OutputStream类型的字节流,而PrintWriter既可以封装OutputStream类型的字节流,还能够封装Writer类型的字符输出流并增强其功能。
参考文献
感谢并致敬以下前辈的文章: